
 免费 AI IDE
免费 AI IDE

微服务架构之RPC-client序列化细节
通过上篇文章的介绍,知道了要实施微服务,首先要搞定RPC框架,RPC框架的职责要向【调用方】和【服务提供方】屏蔽各种复杂性:
(1)让调用方感觉就像调用本地函数一样
(2)让服务提供方感觉就像实现一个本地函数一样来实现服务
整个RPC框架又分为client部分与server部分:
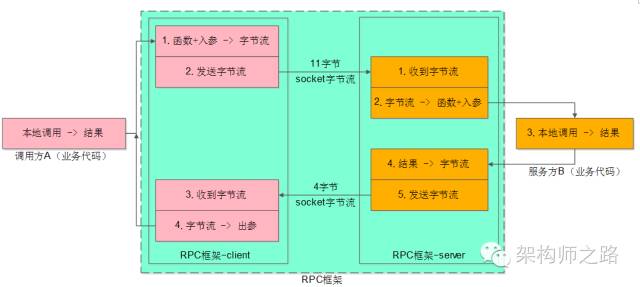
RPC-client的部分流程如上图,要进行序列化反序列化(上图中的1、4),要进行发送字节流与接收字节流(上图中的2、3)。
通过上一篇文章的用户调研:
78%读者 -> 继续聊RPC框架技术细节
14%读者 -> 聊微服务其他实践
7%读者 -> 不聊微服务了,聊最终一致性
那么按照多数读者的意见,今天深入聊RPC的技术细节,本文先讨论RPC-client部分的【序列化反序列化】实施细节(笔者不是这方面的专家,有不对之处,欢迎大家指正,任何具有建设性意见的留言,将在下一章share给更多的小伙伴)。
一、为什么要进行序列化
工程师通常使用“对象”来进行数据的操纵:
class User{std::Stringuser_name;
uint64_tuser_id;
uint32_tuser_age;
};
User u = new User(“shenjian”);
u.setUid(123);
u.setAge(35);
但当需要对数据进行存储(固化存储,缓存存储)或者传输(跨进程网络传输)时,“对象”就不这么好用了,往往需要把数据转化成连续空间的二进制字节流,一些典型的场景是:
(1)数据库索引的磁盘存储:数据库的索引在内存里是b+树或者hash的格式,但这个格式是不能够直接存储到磁盘上的,所以需要把b+树或者hash转化为连续空间的二进制字节流,才能存储到磁盘上
(2)缓存的KV存储:redis/memcache是KV类型的缓存,缓存存储的value必须是连续空间的二进制字节流,而不能够是User对象
(3)数据的网络传输:socket发送的数据必须是连续空间的二进制字节流,也不能是对象
所谓序列化(Serialization),就是将“对象”形态的数据转化为“连续空间二进制字节流”形态数据的过程,以方便存储与传输。这个过程的逆过程叫做反序列化。
二、怎么进行序列化
这是一个非常细节的问题,要是让你来把“对象”转化为字节流,你会怎么做?很容易想到的一个方法是xml(或者json)这类具有自描述特性的标记性语言:
<class name=”User”><element name=”user_name” type=”std::String” value=”shenjian” />
<element name=”user_id” type=”uint64_t” value=”123” />
<element name=”user_age” type=”uint32_t” value=”35” />
</class>
规定好转换规则,发送方很容易把User类的一个对象序列化为xml,服务方收到xml二进制流之后,也很容易将其范序列化为User对象(特别是语言支持反射的时候,就更easy了)。
第二个方法是自己实现二进制协议来进行序列化,还是以上面的User对象为例,可以设计一个这样的通用协议:

(1)头4个字节表示序号
(2)序号后面的4个字节表示key的长度m
(3)接下来的m个字节表示key的值
(4)接下来的4个字节表示value的长度n
(5)接下来的n个字节表示value的值
(6)像xml一样递归下去,直到描述完整个对象
上面的User对象,用这个协议描述出来可能是这样的:
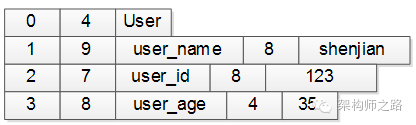
(1)第一行:序号4个字节(设0表示类名),类名长度4个字节(长度为4),接下来4个字节是类名(”User”),共12字节
(2)第二行:序号4个字节(1表示第一个属性),属性长度4个字节(长度为9),接下来9个字节是属性名(”user_name”),属性值长度4个字节(长度为8),属性值8个字节(值为”shenjian”),共29字节
(3)第三行:序号4个字节(2表示第二个属性),属性长度4个字节(长度为7),接下来7个字节是属性名(”user_id”),属性值长度4个字节(长度为8),属性值8个字节(值为123),共27字节
(4)第四行:序号4个字节(3表示第三个属性),属性长度4个字节(长度为8),接下来8个字节是属性名(”user_name”),属性值长度4个字节(长度为4),属性值4个字节(值为35),共24字节
整个二进制字节流共12+29+27+24=92字节
实际的序列化协议要考虑的细节远比这个多,例如:强类型的语言不仅要还原属性名,属性值,还要还原属性类型;复杂的对象不仅要考虑普通类型,还要考虑对象嵌套类型等。however,序列化的思路都是类似的。
三、序列化协议要考虑什么因素
不管使用成熟协议xml/json,还是自定义二进制协议来序列化对象,序列化协议设计时要考虑哪些因素呢?
(1)解析效率:这个应该是序列化协议应该首要考虑的因素,像xml/json解析起来比较耗时,需要解析doom树,二进制自定义协议解析起来效率就很高
(2)压缩率,传输有效性:同样一个对象,xml/json传输起来有大量的xml标签,信息有效性低,二进制自定义协议占用的空间相对来说就小多了
(3)扩展性与兼容性:是否能够方便的增加字段,增加字段后旧版客户端是否需要强制升级,都是需要考虑的问题,xml/json和上面的二进制协议都能够方便的扩展
(4)可读性与可调试性:这个很好理解,xml/json的可读性就比二进制协议好很多
(5)跨语言:上面的两个协议都是跨语言的,有些序列化协议是与开发语言紧密相关的,例如dubbo的序列化协议就只能支持Java的RPC调用
(6)通用性:xml/json非常通用,都有很好的第三方解析库,各个语言解析起来都十分方便,上面自定义的二进制协议虽然能够跨语言,但每个语言都要写一个简易的协议客户端
(7)欢迎大家补充…
四、业内常见的序列化方式
(1)xml/json:解析效率,压缩率都较差;扩展性、可读性、通用性较好
(2)thrift:没有用过,欢迎大家补充
(3)protobuf:Google出品,必属精品,各方面都不错,强烈推荐,属于二进制协议,可读性差了点,但也有类似的to-string协议帮助调试问题
(4)Avro:没有用过,欢迎大家补充
(5)CORBA:没有用过,欢迎大家补充
(6)mc_pack:懂的同学就懂,不懂的就不懂了,09年用过,传说各方面都超越protobuf,懂行的同学可以说一下现状
(7)…
五、后文预告
RPC-client的部分,除了要进行序列化反序列化,还要进行发送字节流与接收字节流,下一篇文章会介绍这一部分内容。
RPC-client中数据的发送与接收远比序列化反序列化复杂,其涉及“连接池、负载均衡、故障转移、队列、超时、异步、上下文回调管理”等技术,具体细节,下篇再沟通。


更多建议: