
 免费 AI IDE
免费 AI IDE

mysql并行复制降低主从同步延时的思路与启示
一、缘起
mysql主从复制,读写分离是互联网用的非常多的mysql架构,主从复制最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重。
为什么mysql主从延时这么大?
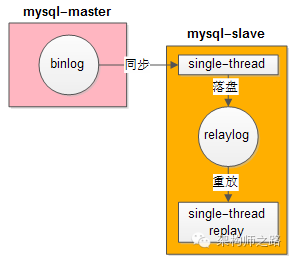
回答:从库使用【单线程】重放relaylog。
优化思路是什么?
回答:使用单线程重放relaylog使得同步时间会比较久,导致主从延时很长,优化思路不难想到,可以【多线程并行】重放relaylog来缩短同步时间。
mysql如何“多线程并行”来重放relaylog,是本文要分享的主要内容。
二、如何多线程并行重放relaylog

通过多个线程来并行重放relaylog是一个很好缩短同步时间的思路,但实施之前要解决这样一个问题:
如何来分割relaylog,才能够让多个work-thread并行操作数据data时,使得data保证一致性?
首先,【随机的分配relaylog肯定是不行的】,假设relaylog中有这样三条串行的修改记录:
update account set money=100 where uid=58;
update account set money=150 where uid=58;
update account set money=200 where uid=58;
串行执行:肯定能保证与主库的执行序列一致,最后得到money=200
随机分配并行执行:3个工作线程并发执行这3个语句,谁最后执行成功是不确定的,故得到的数据可能与主库不同
好,对于这个问题,可以用什么样的思路来解决呢(大伙怎么想,mysql团队其实也就是这么想的)
【方法一:相同库上的写操作,用相同的work-thread来重放relaylog;不同库上的写操作,可以用多个work-thread并发来重放relaylog】
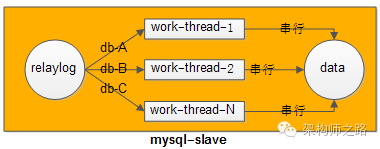
如何做到呢?
回答:不难,hash(db-name) % thread-num,库名hash之后再模上线程数,就能够做到。
存在的不足?
很多公司对mysql的使用是“单库多表”,如果是这样的话,仍然是同一个work-thread在串行执行,还是不能提高relaylog的重放速度。
优化方案:将“单库多表”的模式升级为“多库多表”的模式。
其实,数据量大并发量大的互联网业务场景,“多库”模式还具备着其他很多优势,例如:
(1)非常方便的实例扩展:dba很容易将不同的库扩展到不同的实例上
(2)按照业务进行库隔离:业务解耦,进行业务隔离,减少耦合与相互影响
(3)…
对于架构师进行架构设计的启示是:使用多库的方式设计db架构,能够降低主从同步的延时。
新的想法:“单库多表”的场景,还有并行执行优化余地么?
仔细回顾和思考,即使只有一个库,数据的修改和事务的执行在主库上也是并行操作的,既然在主库上可以并行操作,在从库上为啥就不能并行操作,而要按照库来串行执行呢(表示不服)?
新的思路:将主库上同时并行执行的事务,分为一组,编一个号,这些事务在从库上的回放可以并行执行(事务在主库上的执行都进入到prepare阶段,说明事务之间没有冲突,否则就不可能提交),没错,mysql正是这么做的。
【方法二:基于GTID的并行复制】
新版的mysql,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=120160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=2
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=3
20160607 23:22 server_id 58 XXX GTID last_committed=0 sequence_numer=4
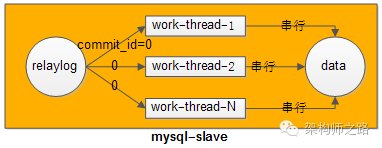
和原来的日志相比,多了last_committed和sequence_number。
last_committed表示事务提交时,上次事务提交的编号,如果具备相同的last_committed,说明它们在一个组内,可以并发回放执行。
三、结尾
从mysql并行复制缩短主从同步时延的思想可以看到,架构的思路是相同的:
(1)多线程是一种常见的缩短执行时间的方法
(2)多线程并发分派任务时必须保证幂等性:mysql的演进思路,提供了“按照库幂等”,“按照commit_id幂等”两种方式,思路大伙可以借鉴
另,mysql在并行复制上的逐步优化演进:
mysql5.5 -> 不支持并行复制,对大伙的启示:升级mysql吧
mysql5.6 -> 按照库并行复制,对大伙的启示:使用“多库”架构吧
mysql5.7 -> 按照GTID并行复制
我不是mysql的开发人员,也不是专业的dba,本文仅为一个思路的分享,希望大伙有收获,如果不对也欢迎随时指出。


更多建议: