
 免费 AI IDE
免费 AI IDE

创业公司快速搭建立体化监控之路(WOT2016)
一、需求缘起
创业型公司有系统监控么?来看两个case:
case 1:CXO大群内贴了一张“用户微信投诉”的截图
(1)CXO大群内贴了一张“用户微信投诉”的截图
(2)技术反馈“正在跟进”
(3)10分钟之后,CXO询问进度,技术反馈“正在解决”
(4)60分钟之后,CXO说怎么还没有解决,技术反馈“正在解决”
实际上,可能还没有找到问题在哪里。
case 2:用户通过客服反馈功能不可用
(1)用户反馈到客服,不能下单
(2)客服 -> 产品 -> 测试 -> 技术
(3)技术:站点层 -> 服务层1 -> 服务层2 -> 数据层
可能2个小时过去了,技术还没有定位到问题在哪一层。
存在的问题:技术被动
(1)出了问题成为最后知晓者,用户受影响周期长
(2)查找问题路径长,定位和修复问题时间久,用户受影响周期长
所有系统负责人能快速回答这两个问题么
(1)所负责的系统现在运行是否正常?
(2)如果不正常,问题大致在哪里?
今天的主题是“创业型公司如何快速解决这两个问题”
二、解决方案:立体化监控
怎么知道系统运行是否正常?
回答:监控
什么是立体化监控?
回答:多维度监控
监控维度有哪些?
回答:(1)机器、操作系统层面
(2)进程、端口层面
(3)日志层面
(4)接口层面
(5)用户层面
三、创业型公司如何快速实现立体化监控
【如可快速实现机器、操作系统级别的监控?】
回答:zabbix,用过的都说好
不足:CPU,LOAD,内存,网络,磁盘异常说明系统一定异常,但这些参数正常并不能说明系统正常,例如:进程挂了,端口挂了,通过这些参数就检测不到
【如何快速实现进程、端口级别的监控?】
两类实现思路:分发型监控 + 汇总型监控
分发型监控
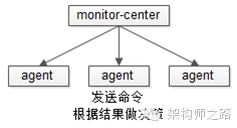
命令由监控中心分发到各个被监控机器的agent上,agent执行监控,实现要点:
(1)监控中心要实现扩展性较强的配置,方便扩展“监控哪个ip上哪个进程或者端口的存活性”
(2)对于进程与端口的监控,甚至无需agent来执行,直接使用带超时的端口连接或者telnet就能快速实现
汇总型监控
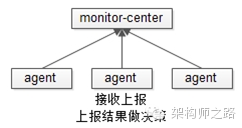
命令由agent在各台机器上执行,将结果汇总上报到监控中心接口,实现要点:
(1)agent必须能够快速部署到所有的机器
(2)agent如何快速从监控中心获取需要监控的进程和端口,必须要保证扩展性
(3)agent如何快速的执行本地检测,例如:进程监控用ps?端口监控用netstat?
进程与端口监控的不足:进程与端口异常说明系统一定异常,但它们正常并不能说明系统正常,例如:进程和端口都在,但ERROR日志狂刷
【如何快速实现日志的监控?】
两类实现思路:ERROR日志的监控 + 日志关键字监控
这两类实现又有“日志各机器单独监控”与“日志汇总到中心监控”两种方法,暂时不展开。
ERROR日志监控快速实施要点
(1)日志分级规范非常重要,需要进行日志按照级别分离,ERROR日志单独拿出来一个文件是最好的
(2)日志切分规范也很重要,建议按照小时切分
(3)1和2的目的,是为了保证扩展性,并减少扫描的日志量,做到了1和2之后,例如用一个crontab,设定一定阈值,每分钟wc -l ERROR文件,超过阈值就可以报警
(4)简易的配置与良好的扩展性,需要支持方面的增加“某一台机器”“某一个路径”“ERROR每分钟超过多少”的报警配置
日志关键字监控
和ERROR日志监控的思路是类似的,当日志中出现一些事先设定的关键字(或者出现频率超过一定阈值),例如exception、timeout就报警,这种报警能够报出比ERROR更精准的系统异常
ERROR日志监控与日志关键字监控的不足:ERROR日志超过阈值说明系统一定异常,不超过阈值并不能说明系统正常,例如:进程死锁,此时并不会刷ERROR日志
【如何快速实现接口的监控】
有两种常见的快速实现思路:统一keepalive接口 + 接口处理时间统一上报
统一keepalive接口快速实施要点
(1)在站点框架与服务框架层面统一实现一个keepalive接口
(2)监控中心统一调用站点、服务的keepalive接口
(3)简易的配置与良好的扩展性
接口处理时间统一上报快速实施要点
(1)在站点框架和服务框架层面统一实现处理时间的收集
(2)由于并发量很大,需要在本地进行初步汇总
(3)或者使用upd上报
(4)时间上报需要异步,不要因为这个而增加业务处理时间
(5)良好的配置与扩展性,监控中心统一配置报警(绝对时间,或者处理时间环比增长报警)
统一keepalive接口与接口处理时间统一上报的不足:上报异常说明系统一定异常,上报正常不能说明系统正常,例如:某个服务后端的数据库挂了,此时这个服务的keepalive接口返回其实是正常的,接口的处理时间可能会比平常要快很多(原来数据库还要执行一个sql,现在连接都拿不到,立马就返回了)
【到底什么样的监控,才能说明系统是正常的呢?】
郁闷了,上述多个维度的监控,都不能完全说明系统正常,怎么办?
回答:只有站在调用者的角度,对被调用方的可用性可靠性的评判才是最准确的
思路:模拟调用方调用站点、服务,来对站点和服务进行监控
通用接口监控分层架构图

如上图所示,实现“模拟调用方对站点和服务进行监控”的分层架构
被监控层:被监控的站点和服务,例如A,B,C
发包层:模拟站点和服务调用方的发包器,例如A-sender,B-sender,C-sender
监控中心:调度发包层对站点和服务进行监控,对结果进行管理,对阈值进行判断与实施报警
监控中心又分为这么几个部分:
(1)集群管理:每个被监控服务有哪些ip
(2)监控项管理:监控哪个服务、调度频率、防抖动配置、责任人
(3)责任人管理:责任人、邮箱、手机号、微信号
(4)调度中心:隔多长时间调度每个监控项
(5)发包层通信:获取发包层的监控结果与异常信息
监控流程,用伪代码描述吧:
for(每一个监控项里被监控的服务){ // 其实是并行执行的,并不是for
for(这个服务所对应集群里的每个ip){调度发包层,对服务进行发包;
收集发包层的监控结果与异常信息
if(异常次数超过我们设定的阈值){
找到服务对应的责任人;
异常信息发短信;
发邮件;
发微信;
}
}
}
其他实践:
(1)一个服务提供的接口很多,可以选取最核心的接口进行发包监控
(2)写接口可能会对数据产生污染,建议选取读接口进行监控
(3)如果一定要对写接口进行监控,务必插入操作和删除操作要是成对进行的(还是会对业务数据统计产生污染)
(4)发包层的sender程序可以复用接口测试的代码
(5)发包器的结果校验要进行业务校验,例如一个http请求仅仅检查返回码是200是不够的,还要检测返回的html或者json的内容是更准确的
【什么样的监控,能决定凌晨收到报警而不起床处理呢?】
回答:用户视角的监控
“模拟调用方调用站点、服务,来对站点和服务进行监控”的方法,可以精确的判断有问题的是哪一个ip上的哪一个服务上的哪一个接口,理论上应该是粒度最细的监控了,为什么还需要用户视角的监控呢?
回答:
(1)架构是做了可用性保证的,一个服务挂了,用户视角的监控没有报警,说明对用户没有影响,如果此时凌晨收到报警,也是不需要马上起床来处理的
(2)用户是在全国各地进行访问的,很有可能某个地域的网络出问题,此时只有在全国布点的用户视角监控才能发现
如何快速的实施用户视角的监控:
(1)复用接入层的接口监控,只是,不对每一个web-server的站点ip实施监控,而是对nginx反向代理层实施监控
(2)引入第三方监控
四、总结
创业型公司快速实施立体化多维度监控总结:
(1)机器、操作系统维度监控:zabbix
(2)进程、端口维度监控:分发型监控 + 汇总型监控
(3)错误日志与关键字维度监控
(4)keepalive接口与所有接口统一处理时间统一上报监控
(5)模拟调用方调用站点、服务,来对站点和服务进行监控
到底什么样的监控,才能说明系统是正常的呢?
回答:只有站在调用者的角度,对被调用方的可用性可靠性的评判才是最准确的


更多建议: