
 免费 AI IDE
免费 AI IDE

如何快速实现高并发短文检索
一、需求缘起
某并发量很大,数据量适中的业务线需要实现一个“标题检索”的功能:
(1)并发量较大,每秒20w次
(2)数据量适中,大概200w数据
(3)是否需要分词:是
(4)数据是否实时更新:否
二、常见潜在解决方案及优劣
(1)数据库搜索法
具体方法:将标题数据存放在数据库中,使用like来检索
优点:方案简单
缺点:不能实现分词,并发量扛不住
(2)数据库全文检索法
具体方法:将标题数据存放在数据库中,建立全文索引来检索
优点:方案简单
缺点:并发量扛不住
(3)使用开源方案将索引外置
具体方法:搭建lucene,solr,ES等开源外置索引方案
优点:性能比上面两种好
缺点:并发量可能有风险,系统比较重,为一个简单的业务搭建一套这样的系统成本较高
三、58龙哥的建议
问1:龙哥,58同城第一届编程大赛的题目好像是“黄反词过滤”,你是冠军,当时是用DAT来实现的么?
龙哥:是的
画外音:什么是DAT?
普及:DAT是double array trie的缩写,是trie树的一个变体优化数据结构,它在保证trie树检索效率的前提下,能大大减少内存的使用,经常用来解决检索,信息过滤等问题。(具体大伙百度一下“DAT”)
问2:上面的业务场景可以使用DAT来实现么?
龙哥:DAT更新数据比较麻烦,不能增量
问3:那直接使用trie树可以么?
龙哥:trie树比较占内存
画外音:什么是trie树?
普及:trie树,又称单词查找树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。(来源:百度百科)
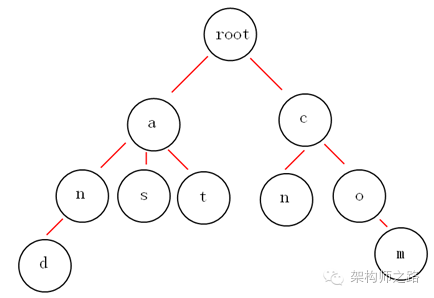
例如:上面的trie树就能够表示{and, as, at, cn, com}这样5个标题的集合。
问4:如果要支持分词,多个分词遍历trie树,还需要合并对吧?
龙哥:没错,每个分词遍历一次trie树,可以得到doc_id的list,多个分词得到的list合并,就是最终的结果。
问5:龙哥,还有什么更好,更轻量级的方案么?
龙哥:用trie树,数据会膨胀文档数*标题长度这么多,标题越长,文档数越多,内存占用越大。有个一个方案,内存量很小,和标题长度无关,非常帅气。
问6:有相关文章么,推荐一篇?
龙哥:可能网上没有,我简单说一下吧,核心思想就是“内存hash + ID list”
索引初始化步骤为:对所有标题进行分词,以词的hash为key,doc_id的集合为value
查询的步骤为:对查询词进行分词,对分词进行hash,直接查询hash表格,获取doc_id的list,然后多个词进行合并
=====例子=====
例如:
doc1 : 我爱北京doc2 : 我爱到家
doc3 : 到家美好
先标题进行分词:
doc1 : 我爱北京 -> 我,爱,北京doc2 : 我爱到家 -> 我,爱,到家
doc3 : 到家美好 -> 到家,美好
对分词进行hash,建立hash + ID list:
hash(我) -> {doc1, doc2}hash(爱) -> {doc1, doc2}
hash(北京) -> {doc1}
hash(到家) -> {doc2, doc3}
hash(美好) -> {doc3}
这样,所有标题的初始化就完毕了,你会发现,数据量和标题的长度没有关系。
用户输入“我爱”,分词后变为{我,爱},对各个分词的hash进行内存检索
hash(我)->{doc1, doc2}hash(爱)->{doc1, doc2}
然后进行合并,得到最后的查找结果是doc1+doc2。
=====例子END=====
问7:这个方法有什么优点呢?
龙哥:存内存操作,能满足很大的并发,时延也很低,占用内存也不大,实现非常简单快速
问8:有什么不足呢?和传统搜索有什么区别咧?
龙哥:这是一个快速过度方案,因为索引本身没有落地,还是需要在数据库中存储固化的标题数据,如果不做高可用,数据恢复起来会比较慢。当然做高可用也是很容易的,建立两份一样的hash索引即可。另外,没有做水平切分,但数据量非常非常非常大时,还是要做水平切分改进的。


更多建议: