

Hadoop是一个开源的分布式计算框架,它的设计目标是能够高效地处理大规模数据集。Hadoop提供了可靠性、高可扩展性和容错性,使得它成为处理大数据的首选解决方案。本文将详细介绍Hadoop的概念、架构以及其核心组件,以帮助读者更好地理解和应用Hadoop。
Hadoop的概念
Hadoop最初是由Apache软件基金会开发的,它是一个基于Java编程语言的分布式计算框架。它的核心思想是将大规模数据集分割成多个小块,并将这些块分布式存储在多台服务器上。Hadoop提供了一个可靠的、高效的分布式计算环境,使得可以在集群中并行处理这些数据块。

Hadoop的架构
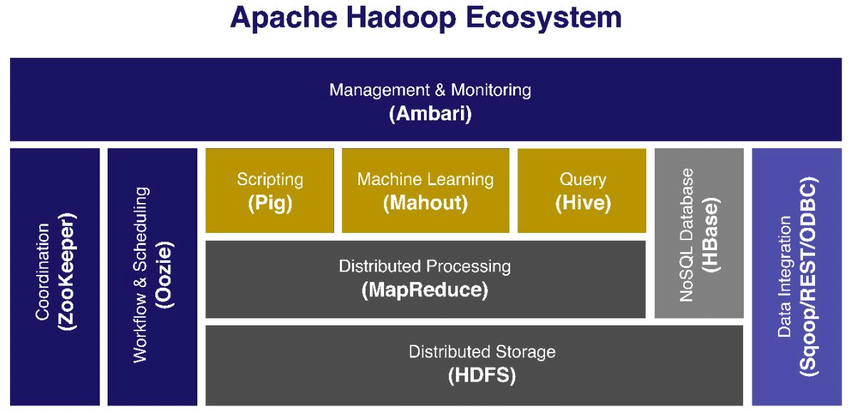
- HDFS: HDFS是Hadoop的分布式文件系统,它用于存储和管理大规模数据集。HDFS将文件分割成多个数据块,并将这些数据块分布式存储在多个服务器上。这种分布式存储方式提供了高可靠性和容错性,使得即使在服务器故障的情况下,数据仍然可靠可用。
- MapReduce: MapReduce是Hadoop的计算模型,它用于并行处理存储在HDFS上的数据。MapReduce将计算任务分为两个阶段:Map阶段和Reduce阶段。Map阶段将输入数据分割成多个独立的子问题,并由多个计算节点并行处理。Reduce阶段将Map阶段的中间结果进行合并和汇总,生成最终的计算结果。
Hadoop的核心组件
- YARN(Yet Another Resource Negotiator): YARN是Hadoop的资源管理器,负责集群资源的分配和管理。它允许多个应用程序共享集群资源,并动态分配和调度这些资源,以提高集群的利用率和性能。
- Hadoop Common: Hadoop Common是Hadoop的共享库,它包含了一些常用的工具和实用程序,用于支持Hadoop的各个组件。
- Hadoop MapReduce(旧版): 旧版的Hadoop MapReduce是Hadoop的初始实现,它提供了基本的MapReduce计算框架。然而,随着Hadoop的发展,新版MapReduce已经成为了更为推荐的计算模型。
Hadoop的优势和应用场景
- 可靠性和容错性:Hadoop通过将数据复制到多个服务器上来提供高可靠性和容错性。即使在某些服务器出现故障的情况下,数据仍然可靠可用。
- 可扩展性:Hadoop可以轻松地扩展到数百甚至数千台服务器,以处理大规模的数据集。
- 并行处理:Hadoop的MapReduce模型允许并行处理大规模数据,提高计算效率。
- 成本效益:Hadoop是开源软件,可以在廉价的硬件上构建大规模的集群,从而降低了成本。
总结
Hadoop是一个开源的分布式计算框架,专为高效处理大规模数据集而设计。它的核心组件包括HDFS和MapReduce,提供了可靠性、可扩展性和容错性。Hadoop的分布式文件系统(HDFS)用于存储和管理数据,而MapReduce计算模型用于并行处理数据。通过并行处理和分布式存储,Hadoop能够处理大规模数据并提供高可靠性。此外,Hadoop还包括YARN资源管理器和Hadoop Common共享库等组件,提供更全面的功能和支持。Hadoop的优势包括可靠性、可扩展性、并行处理和成本效益。它在互联网搜索、社交媒体分析、金融风险建模等领域具有广泛应用。作为一个强大的分布式计算框架,Hadoop为处理大规模数据提供了可靠和高效的解决方案。

如果你对编程知识和相关职业感兴趣,欢迎访问编程狮官网(https://www.w3cschool.cn/)。在编程狮,我们提供广泛的技术教程、文章和资源,帮助你在技术领域不断成长。无论你是刚刚起步还是已经拥有多年经验,我们都有适合你的内容,助你取得成功。



