
 免费 AI IDE
免费 AI IDE


手册简介
Stable Diffusion 中文教程, AI绘画 Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像
手册说明

Stable Diffusion 主要用于根据文本的描述产生详细图像。
它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神經网络。它是由初创公司StabilityAI,CompVis与Runway合作开发的,并得到EleutherAI和LAION的支持。 截至2022年10月,StabilityAI筹集了1.01亿美元的资金。
Stable Diffusion的代码和模型权重已公开发布,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
技术架构
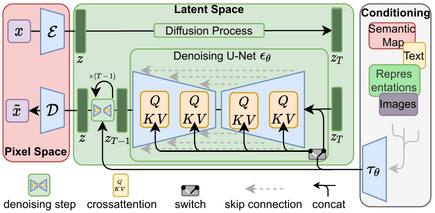
Stable Diffusion是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。
Stable Diffusion由3个部分组成:变分自编码器(VAE)、U-Net和一个文本编码器。
用法

Stable Diffusion模型支持通过使用提示词来产生新的图像,描述要包含或省略的元素,以及重新绘制现有的图像,其中包含提示词中描述的新元素(该过程通常被称为“指导性图像合成”(guided image synthesis))通过使用模型的扩散去噪机制(diffusion-denoising mechanism)。 此外,该模型还允许通过提示词在现有的图中进内联补绘制和外补绘制来部分更改,当与支持这种功能的用户界面使用时,其中存在许多不同的开源软件。
Stable Diffusion建议在10GB以上的VRAM下运行, 但是VRAM较少的用户可以选择以float16的精度加载权重,而不是默认的float32,以降低VRAM使用率。
文生图
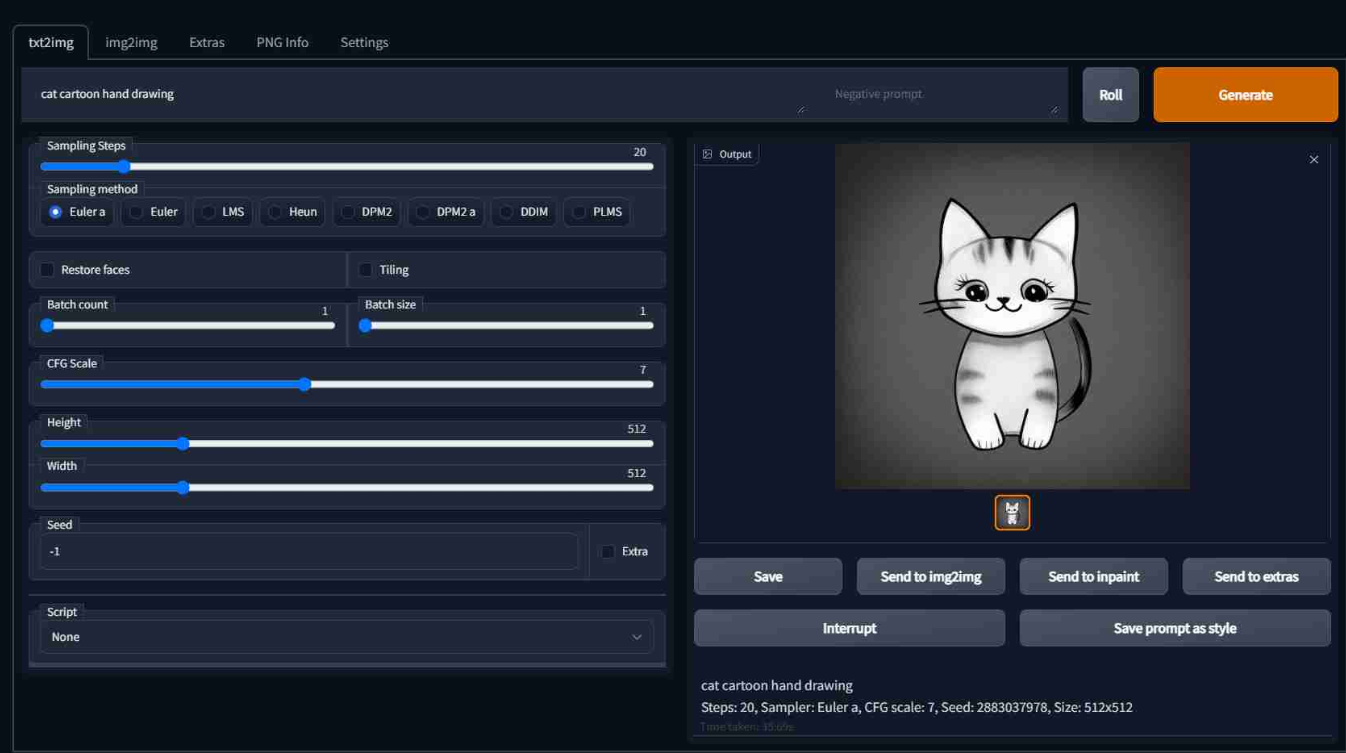
Stable Diffusion中的文生图采样脚本,称为"txt2img",接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。 生成的图像带有不可见的数字水印标签,以允许用户识别由Stable Diffusion生成的图像,尽管如果图像被调整大小或旋转,该水印将失去其有效性。 Stable Diffusion模型是在由512×512分辨率图像组成的数据集上训练出来的,这意味着txt2img生成图像的最佳配置也是以512×512的分辨率生成的,偏离这个大小会导致生成输出质量差。 Stable Diffusion 2.0版本后来引入了以768×768分辨率图像生成的能力。
每一个txt2img的生成过程都会涉及到一个影响到生成图像的随机种子;用户可以选择随机化种子以探索不同生成结果,或者使用相同的种子来获得与之前生成的图像相同的结果。 用户还可以调整采样迭代步数(inference steps);较高的值需要较长的运行时间,但较小的值可能会导致视觉缺陷。
反向提示词(negative prompt)是包含在Stable Diffusion的一些用户界面软件中的一个功能,它允许用户指定模型在图像生成过程中应该避免的提示,适用于由于用户提供的普通提示词,或者由于模型最初的训练,造成图像输出中出现不良的图像特征,例如畸形手脚。 与使用强调符相比,使用反向提示词在降低生成不良的图像的频率方面具有高度统计显著的效果;强调符是另一种为提示的部分增加权重的方法,被一些Stable Diffusion的开源实现所利用,在关键词中加入括号以增加或减少强调。
图生图
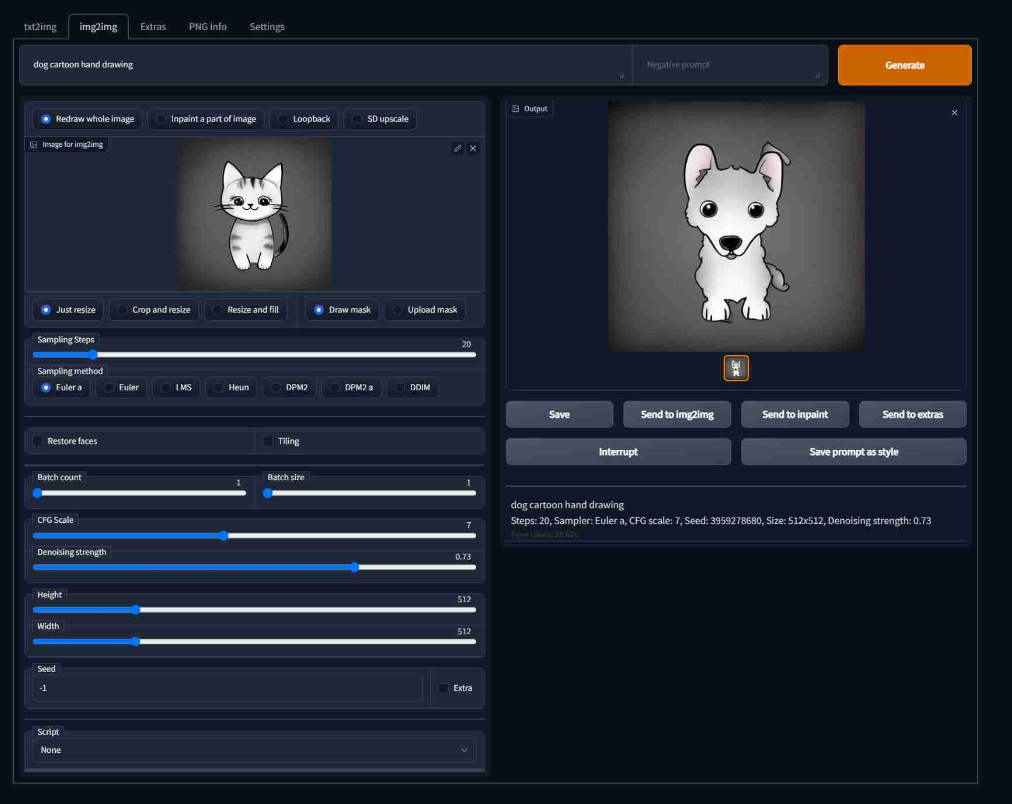
Stable Diffusion包括另一个取样脚本,称为"img2img",它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。 图像升频是img2img的一个潜在用例,除此之外。
2022年11月24日发布的Stable Diffusion 2.0版本包含一个深度引导模型,称为"depth2img",该模型推断所提供的输入图像的深度,并根据提示词和深度信息生成新图像,在新图像中保持原始图像的连贯性和深度。
内补绘制与外补绘制
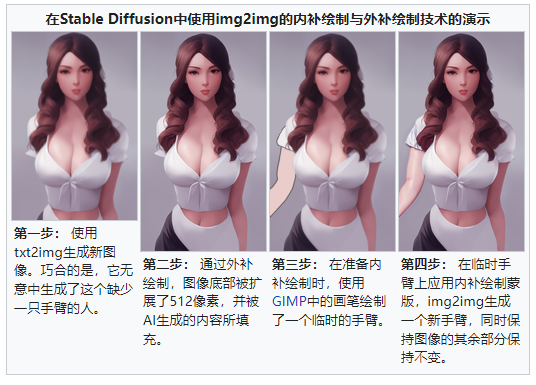
Stable Diffusion模型的许多不同用户界面软件提供了通过img2img进行图生图的其他用例。内补绘制(inpainting)由用户提供的蒙版描绘的现有图像的一部分,根据所提供的提示词,用新生成的内容填充蒙版的空间。 随着Stable Diffusion 2.0版本的发布,StabilityAI同时创建了一个专门针对内补绘制用例的专用模型。 相反,外补绘制(outpainting)将图像扩展到其原始尺寸之外,用根据所提供的提示词生成的内容来填补以前的空白空间。
更新记录
-
stable-diffusion-webui 安装 03-09 16:19
-
文本转图像模型的发展周期 03-08 14:33
-
Transformers 03-08 14:29

