
 免费 AI IDE
免费 AI IDE

pika_to_redis实现过程和分析结果
背景
为满足运维人员对于pika可以更好地运维,需要方便地将数据从pika迁移到redis,在pika系统中之前已经为运维人员提供了Redis请求实时copy到pika工具可以实时将redis上的请求同步发送到pika,这个工具则是为了能够将离线的pika数据迁移至redis。
最终目标
- 保证数据迁移结果的正确性
- 满足目标的条件下,在能够接收的时间下完成任务
实现
版本1:串行可用版
目标
- 走通这个数据迁移的流程,确定实现方案的可行性
- 为下一版本优化方向做准备
方案
使用串行方式,将整个迁移过程分为三个阶段,如下:
- 利用pika数据引擎的接口,将所有数据遍历出来
- 利用得到的数据,生成相对应的redis指令(SET,HSET,RPUSH)
- 使用pika内部的pink::RedisCli接口,将指令发送给redis服务器并接收响应 并在每个阶段计时分析以便后面优化。
结果
验证方案可行,但是速度难以接受,迁移10G数据需要20小时以上。从迁移过程的三个步骤中,可以看到无论是数据扫描还是,指令的发送和接收响应都非常慢。分析其原因,主要在于:
- 单线程,没有发挥机器多核优势
- 在与redis服务器的交互过程为,发送一条数据,并等待一条数据的响应,导致速度很慢
改进措施
在版本1不能满足速度要求之后,发现redis官方客户端提供有一种可以大规模数据插入的方式pipeline mode,使用的基本形式如下:
cat cmd.txt | redis-cli --pipe
# 其中cmd.txt中存的是符合redis协议的指令对现有程序稍加改动,将生成的redis指令直接写入标准输入流,即可使用pipe mode方式,通过千万条数据测试,在本地效果提高30%以上。这种方案速度较之前大幅提升,在于节省了大量浪费在每个指令返回的时间。
但是直接使用这种方案,虽然速度提升不少,完成时间还是不能满足要求。由于这种方式,还是只能使用一个发送端,不方便后期进行多线程的优化。接下来需要自己定制实现pipeline mode
版本2:定制实现pipeline模式
方案
在pika自己实现的客户端中,只能是逐条发送指令,逐条接收。redis官方客户端的实现方式:
- socket_fd 设置为非阻塞
- 使用poll监听socket_fd的状态,调度指令的发送和响应的接收
- 从标准输入流中读入数据(redis指令),放入一个buf中,在将buf中的数据不停写入到socket
- 批量接收redis服务器的响应,并将其解析判断如果出现错误,则将错误显示出来
- 从标准输入流中读不到数据之后,向redis发送一条ECHO指令,用于标示发送结束
实质上官方客户端是将生成指令和发送指令分别放在两个不同的进程中,在这里模拟标准输入和标准输出,则可以自己开一条管道,一端将指令写入,一端读出指令并发送。
结果
在实现了之后,速度确实有提升,但是发现之前官方客户端从标准输入中读入数据是因为使用场景所限制,大可将管道那一层去掉,让自己管理buf,就少了将数据写入内核,有从内核读出过程,只是自己需要维护buf的读写,这是一个典型的生产者消费者模型。在分析完成之后,对pipeline进行小幅的改进。
改进版本:自己管理buf
- 在内存开辟一个数组作为buf,并维护buf的中需要发送的数据长度len和发送数据起始点pos
- 为充分发挥非阻塞发送的优势,将发送部分单独放在一个线程中执行,需要改变len和pos对其加锁
版本3:多客户端并行和多库并行
方案
在完成了上面的版本之后,就可以对整个流程进行多线程的优化。由于当前数据的发送并非是整条发送出去,buf的管理都粒度都是在字符级别,所以采用一个指令生成线程(parser)和发送线程(sender)一一对应。
- 多客户端并行:建立一个线程池,parser和sender线程组成一个线程组。
- 多库并行:由于nemo底层上,不同数据格式的管理都有一个自己rocksdb实例,所以多库并行,做起来也是非常简便的。最终结果能够提升10%左右。
整体架构图如下:
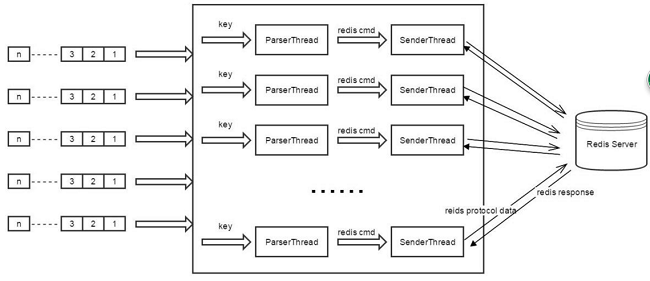
migrator线程
- 扫描不同数据类型的分库
- 将扫描到key分发给parser线程
parser线程
- 接收migrator发送的key
- 将key进行解析成响应数据redis指令
- 将解析好的redis指令加载到sender的发送buf中
sender线程
- 从发送buf中读取数据,以非阻塞方式向redis发送数据
- 接收redis返回的结果并解析,如果出现错误则显示错误结果
结果
至此,数据迁移工具在性能上已经从原先需要20小时迁移的数据到现在大概40分钟左右,完全满足最初的时间要求。
测试
测试结果:
- 在每个同时使用10个发送端(可配置)情况下,不同机器之间每小时平均能够转移15G
- 测试结果,均得到正确性验证
测试分析:
- 数据条数对速度影响比数据量更大,见Test2
- 并行线程越多,速度越快,见Test3
- 本地迁移比不同机器上速度快50%左右,见Test4
测试说明
机器配置说明:
| 名称 | 内存 | cpu |
|---|---|---|
| bada05 | 160G | 24*2.6Hz |
| bada06 | 160G | 24*2.6Hz |
测试数据源说明:
| 名称 | key长度 | 亿条数据磁盘占用 | 1G数据数据条数 |
|---|---|---|---|
| 长数据 | 30字符 | 2.1G | 0.46亿条 |
| 短数据 | 180字符 | 6.3G | 0.15亿条 |
性能测试
Test1:远程测试
bada05->bada06 短数
| 数据库 | 客户端数量 | 数据量 | 数据条数 | 消耗时间 | 速度(每小时) |
|---|---|---|---|---|---|
| All | 10 | 15.6G | 1.5亿*5 | 3.5小时 | 4.5G/2.2亿 |
| kv | 10 | 1.2G | 1.5亿 | 32min | 2.3G/2.8亿 |
| hash | 10 | 3.2G | 1.5亿 | 45min | 4.3G/2亿 |
| set | 10 | 2.8G | 1.5亿 | 40min | 4.2G/2.3亿 |
| zset | 10 | 5.6G | 1.5亿 | 41min | 8.2G/2.2亿 |
Test2:数据源的影响
远程测试:bada05->bada06
数据库| 发送端数量| 数据量| 数据条数 |消耗时间| 速度(每小时) ---|---|---|---|---|---|---|---|---|---|---|--- All(短)| 10| 16G| 1.5亿*5 |3.5h| 4.5G/2.1亿 set(短)| 10| 2.8G| 1.5亿 |40min| 4.2G/2.3亿 set(长)| 10| 2.5G |3.8千万 |10min |15G/2.2亿 hash(长)| 10| 3.3G|3.8千万 |10min |20G/2.2亿 kv(长)| 10| 1.6G| 3.8千万| 8min| 12G/2.8亿 list(长)| 10| 2.8|3.8千万| 10min| 16G/2.2亿 注:由于长数据中,不同数据类型key有重复,无法正常导入redis,故采用分库导入
Test3:发送线程数量的影响
bada05->bada06 短数据
线程数量| 数据量|数据条数 |消耗时间| 速度(每小时) ---|---|---|---|---|---|---|---|--- 10| 16G| 1.5亿5| 3.5小时| 4.5G/2.1亿 16| 16G| 1.5亿5| 2.3小时| 7.1G/3.3亿 20| 16G| 1.5亿*5| 2.1小时| 7.5G/3.5亿
Test4:本地和远程对比
|线程数量| 数据量| 数据条数| 速度(每小时) ---|---|---|---|---|---|--- 异地|10 |16G |1.5亿5| 3.5h 4.5G/2.1亿 本地|10 |16G |1.5亿5| 1.9h 8.1G/3.8亿
正确性测试
测试方法:
- 压入一批pika数据,每条数据的key,都有唯一的顺序的序列号
- 迁移完毕之后。向redis发送不同数据get请求,得到返回之后与预期结果做对比
测试结果:
- 本地迁移不同类型数据各1000万条,完全通过
- 远程迁移不同数据各1000万条,完全通过


更多建议: