在C语言中的结构体用来将相关的数据集合到一个组合变量中。这项技术有几个优点:
1. 通过展示定义在结构体内的数据是紧密相联的来使代码变得清晰明了。
2. 它使传递数据给函数变得简单。代替单独地传递多个变量,它通过传递一个单元来传递多个变量。
3. 它增加了代码的局部性 。
从汇编语言的观点看,结构体可以认为是拥有不同大小的元素的数组。而真正的数组的元素的大小和类型总是一样的。如果你知道数组的起始地址,每个元素的大小和需要的元素的下标,有这个特性就能计算出这个元素的地址。
结构体中的元素的大小并不一定要是一样的(而且通常情况下是不一样的)。因为这个原因,结构体中的每个元素必须清楚地指定而且需要给每个元素一个标号(或者名称),而不是给一个数字下标。
在汇编语言中,结构体中的元素可以通过和访问数组中的元素一样的方法来访问。为了访问一个元素,你必须知道结构体的起始地址和这个元素相对于结构体的相对偏移地址。但是,和数组不一样的是:不可以通过元素的下标来计算该偏移地址,结构体的元素的地址需要通过编译器来赋值。
例如,考虑下面的结构体:
struct S {
short int x; /* 2个字节的整形 */
int y; /* 4个字节的整形 */
double z; /* 8个字节的浮点数 */
};
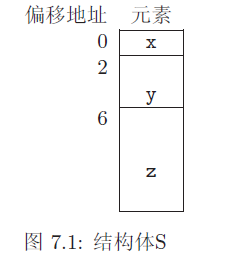
图7.1展示了一个S结构体变量在电脑内存中是如何储存的。ANSIC标准规定结构体中的元素在内存中储存的顺序和在struct定义中的顺序是一样的。它同样规定第一个元素需恰好在结构体的起始地址中(也
就是说偏移地址为0)。它同样在stddef.h头文件中定义了另一个有用的宏offsetof()。这个宏用来计算和返回结构体中任意元素的偏移地址。这个宏携带两个参数,第一个是结构体类型的变量名,第二个是需要得到偏移地址的元素名。因此,图7.1中的,offsetof(S, y)的结果将是2。
内存地址对齐
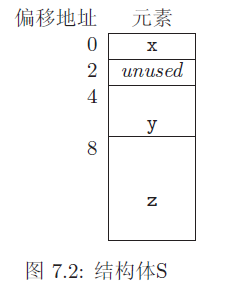
如果在gcc编译器中你使用offsetof宏来得到y的偏移地址,那么它们将找到并返回4,而不是2!为回想一下一个地址如果除 什么呢? 因此gcc(和其它许多编译器),在缺省情况下,变量是对齐在双字界上的。在32位保护模式下,如果数据是从双字界开始储存的,那么CPU能快速地读取内存。图7.2展示了如果使
用gcc,那么S结构体在内存中是如何储存的。编译器在结构体中插入了两个没有使用的字节,用来将y(和z)对齐在双字界上。这就表明了在C中定义的结构体,使用offsetof计算偏移来代替元素自己来计算自己的偏移为什么是一个好的想法。
当然,如果只是在汇编程序中使用结构体,程序员可以自己决定偏移地址。但是,如果你需要使用C和汇编的接口技术,那么在汇编代码和C代码中约定好如何计算结构体元素的偏移地址是非常重要的!一个麻烦的地方是不同的C编译器给出的元素的偏移地址是不同的。例如:就像我们已经知道的,gcc编译器创建结构体S如图7.2;但是,Borland的编译器将创建结构体如图7.1。C编译器提供了指定数据对齐的方法。但是,ANSI C标准并没有指定它们该如何完成,因此不同的编译器使用不同的方法来完成内存地址对齐。
gcc编译器有一个灵活但是复杂的方法来指定地址对齐。它允许你使用特殊的语法来指定任意类型的地址对齐。例如,下面一行:
typedef short int unaligned _int _attribute_ (( aligned (1)));
定义了一个名为unaligned_int的新类型,它采用的是字节界对齐方式。(是的,所以在__attribute__ 后面的括号都是需要的!)aligned的参数1可以用其它的2的乘方值来替代,用来表示采用的是其它对齐方式。(2为字边界,4表示双字界,等等。)如果结构体里的y元素改为unaligned_int类型,那么gcc给出的y的偏移地址为2.但是,z依然处在偏移地址8的位置,因为双精度类型的缺省对齐方式为双字对齐。要想z的偏移地址为6,那么还要改变它的类型定义。
gcc编译器同样允许你压缩一个结构体。它告诉编译器使用尽可能小的空间来储存这个结构体。图7.3展示了S如何以这种方法来定义。这种形式下的S将使用可能的最少的字节数,14个字节。
Microsoft和Borland的编译器都支持使用#pragma指示符的方法来指定对齐方式。
#pragma pack(1)
上面的指示符告诉编译器采用字节界的对齐方式来压缩结构体中的元素。(也就是说,没有额外的填充空间)。其中的1可以用2,4,8或16代替,分别用来指定对齐方式为字边界,双字界,四字界和节边界。这个指示符在被另一个指示符置为无效之前保持有效。这就可能会导致一些问题,因为这些指示符通常使用在头文件中。如果这个头文件在包含结构体的其它头文件之前被包含到程序中,那么这些结构体的放置方式将和它们缺省的放置方式不同。这将导致非常严重的查找错误。程序中的不同模块将会将结构体元素放置在不同的地方。
有一个方法来避免这个问题。Microsoft和Borland都支持这个方法:保存当前对齐方式状态值和随后恢复它。图7.4展示了如何使用这种方法。
位域s
位域允许你指定结构体中的成员的大小为只使用指定的比特位数。比特位数的大小并不一定要是8的倍数。一个位域成员的定义和unsigned int或int的成员定义是一样,只是在定义的后面增加了冒号和位数的大小。图7.5展示了一个例子。它定义了一个32位的变量,它由下面的几部分组成:
第一个位域被指定到此双字的最低有效位处。
但是,如果你看了这些比特位实际上在内存中是如何储存的,你就会发现格式并不是如此简单。难点发生在当位域跨越字节界时。因为在little endian处理器上的字节将以相反的顺序储存到内存中。例如,S结构体在内存中将如下所示:
f2l变量表示f2 位域的末尾五个比特位(也就是,五个最低有效位)。f2m变量表示f2 的五个最高有效位。双垂直线的地方表示字节界。如果你将所有的字节反向,f2 和f3 位域将重新结合到正确的位置。
物理内存的放置方式通常并不是很重要,除非有数据需要传送到程序中或从程序中传出(实际上这和位域是非常相同的)。硬件设备的接口使用奇数的比特位是非常普遍的,此时使用位域来描述是非常有用的。
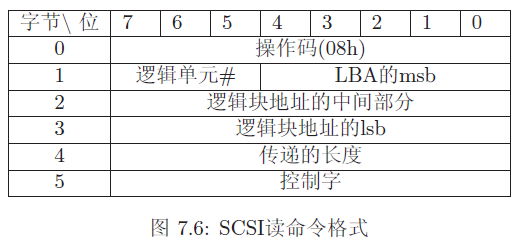
SCSI就是一个例子。SCSI设备的直接读命令被指定为传送一个六个字节的信息到设备,格式指定为图7.6中的格式。使用位域来描述这个的难点是逻辑区块地址(logical block address),它在此命令中跨越了三个不同的字节。从图7.6中,你可以看到数据是以big endian的格式储存的。
图7.7展示了一个试图在所有编译器中工作的定义。前两行定义了一个宏,如何代码是由Microsoft或Borland编译器来编译时,则它就为真。可能比较混乱的部分是11行到14行。首先,你可能会想为什么lba_ mid和lba_lsb 位域要分开被定义,而不是定义成一个16位的域?原因是数据是以big en-dian顺序储存的。而编译器将把一个16位的域以little endian顺序来储存。
其次,lba_msb和logical_unit 位域看起来似乎方向反了;但是,情况并不是这样。它们必须得以这样的顺序来摆放。图7.8展示了作为一个48位的实体,它的位域图是怎样的。(字节界同样是以双垂直线来表示。)当它在内存中是以little endian的格式来储存,那么比特位将以要求的格式来排列。(图7.6)
考虑得复杂一点,我们知道SCSI_read cmd的定义在Microsoft C编译器中不能完全正确工作。如果sizeof (SCSI read cmd)表达式被赋值了,MicrosoftC将返回8,而不是6!这是因为Microsoft编译器使用位域的类型来决定如何绘制比特图。因为所有的位域都被定义为unsigned类型,所以编译器在结构体的末尾加了两个字节使得它成为一个双字类型的整数。这个问题可以通过用unsignedshort替代所有的位域定义类型来修正。现在,Microsoft编译器不需要增加任何的填充字节,因为六个字节是两个字节字类型的整数。4有了这个改变,其它的编译器也能正确工作。图7.9展示了另外一种定义,能在所有的三种编译器上工作。它通过使用unsignedchar避免了除2位的域以外的所有位域的问题。
如果发现前面的讨论非常混乱的读者,请不要气馁。它本来就是混乱的!通过经常完全地避免使用位域而采用位操作来手动地检查和修改比特位,作者发现能避免一些混乱。
在汇编语言中使用结构体
在汇编语言中访问结构体就类似于访问数组。作为一个简单的例子,考虑一下你如何写这样一个汇编程序:将0写入到S结构体的y中。假定这个程序的原型是这样的:
void zero_y( S * s_p );
汇编程序如下:

C语言允许你把一个结构体当作数值传递给函数;但是,通常这都是一个坏主意。当以数值来传递时,在结构体中的所有数据都必须复制到堆栈中,然后在程序中再拿出来使用。用一个结构体指针来替代能有更高的效率。
C语言同样允许一个结构体类型作为一个函数的返回值。很明显,一个结构体不能通过储存到EAX寄存器中来返回。不同的编译器处理这种情况的方法也不同。一个编译器普遍使用的解决方法是在内部重写函数,让它携带一个结构体指针参数。这个指针用来将返回值放入到结构体中,这个结构体是在调用的程序外面定义的。
大多数汇编器(包括NASM)都有在你的汇编代码中定义结构体的内置支持。查阅你的资料来得到更详细的信息。
带一个结构体指针参数。这个指针用来将返回值放入到结构体中,这个结构体是在调用的程序外面定义的。
大多数汇编器(包括NASM)都有在你的汇编代码中定义结构体的内置支持。查阅你的资料来得到更详细的信息。

 免费 AI IDE
免费 AI IDE










更多建议: