


Teradata 散列算法
2018-01-12 15:00 更新
基于主索引值将行分配给特定的AMP。 Teradata使用散列算法来确定哪个AMP获取行。
以下是散列算法的高级图。
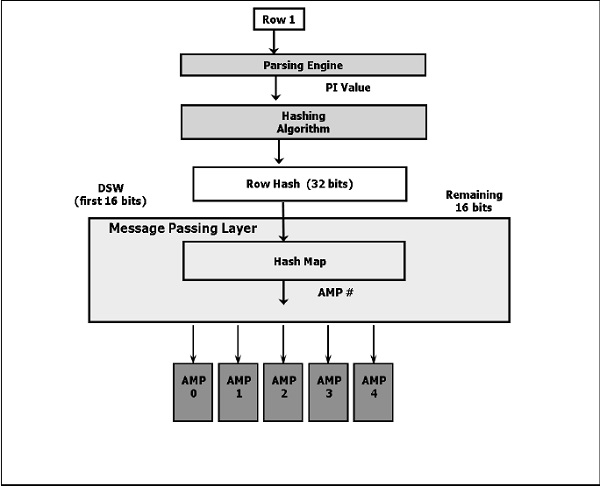
以下是插入数据的步骤。
客户端提交查询。
解析器接收查询并将记录的PI值传递给散列算法。
散列算法散列主索引值,并返回一个32位数,称为行散列。
散列算法散列主索引值,并返回一个32位数,称为行散列。...
BYNET将数据发送到标识的AMP。
AMP使用32位行散列来定位其磁盘中的行。
如果存在具有相同行散列的任何记录,则它递增作为32位数的唯一性ID。 对于新行散列,唯一性ID分配为1,并在每次插入具有相同行散列的记录时递增。
行散列和唯一性ID的组合称为行ID。
行ID为磁盘中的每个记录。
AMP中的每个表行都按其行ID进行逻辑排序。
如何存储表
表按其行ID(行散列+唯一性id)排序,然后存储在AMP中。 行ID与每个数据行一起存储。
| 行哈希 | 唯一性ID | 员工不 | 名字 | 姓 |
|---|---|---|---|---|
| 2A01 2611 | 2A01 2611... | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |
以上内容是否对您有帮助:

更多建议: