
 免费 AI IDE
免费 AI IDE

架构师之路-如何建立高可用消息中间件kafka
一、熟悉kafka
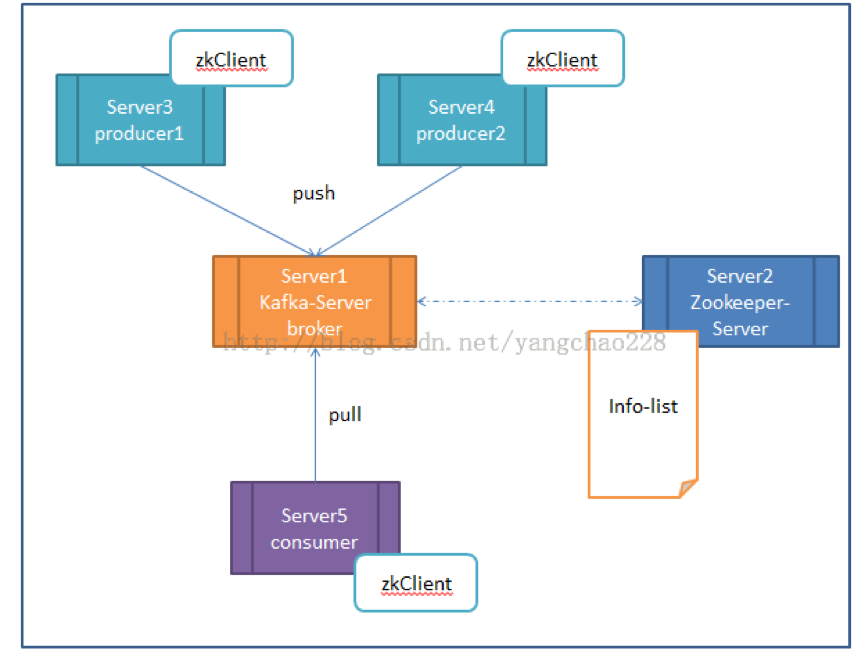
l Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
l Server-2是zookeeper的server端,zookeeper的具体作用你可以去官网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
l Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
l Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
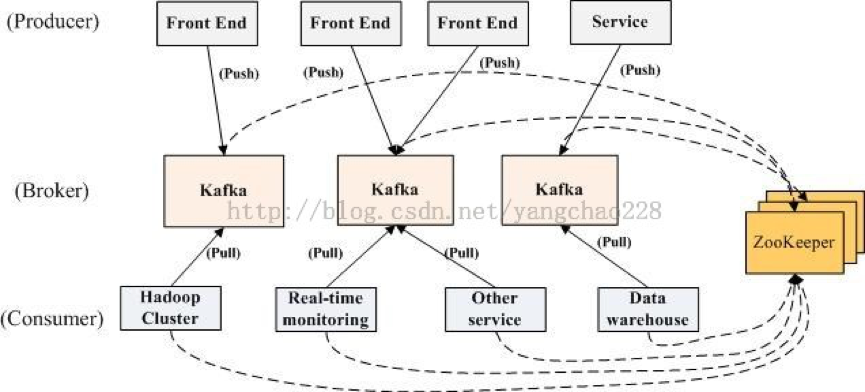
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。
Kafka 分布式消息队列 类似产品有JBoss、MQ
一、由Linkedln 开源,使用scala开发,有如下几个特点:
(1)高吞吐
(2)分布式
(3)支持多语言客户端 (C++、Java)
二、组成: 客户端是 producer 和 consumer,提供一些API,服务器端是Broker,客户端提供可以向Broker内发布消息、消费消息,服务器端提供消息的存储等功能
Kafka 特点是支持分区、分布式、可拓展性强
三、Kafka 的消息分几个层次
(1)Topic 一类主题
(2)Partition 默认每个消息有2个分区,创建Topic可以指定分区数,1天有 1亿行可以分8个分区,如果每天几十万行就一个分区吧
(3)Message 是每个消息
四、数据处理流程
1.生产者 生产消息、将消息发布到指定的topic分区
2.kafka 集群接收到producer发过来的消息后,将其持久化到硬盘,可以指定时长,而不关注消息是否被消费
3.consumer从kafka集群pull或push方式,并控制获取消息的offset偏移量,consumer重启时需要根据offset开始再次消费数据,consumer自己维护offset
五、kafka如何实现高吞吐量
1.充分利用磁盘的顺序读写2.数据批量发送3.数据压缩4.Topic划分多个partition
六、kafka 如何实现load balance &HA
1)producer 根据用户指定的算法,将消息发送到指定的partition2)存在多个partition,每个partition存在多个副本replica,每个replica分布在不同的broker节点上3)每个partition需要选取lead partition,leader partition负责读写,并由zookeeper负责fail over 快速失败4)通过zookeeper管理broker与consumer的动态加入与离开
七、扩容
当需要增加broker节点时,新增的broker会向zookeeper注册,而producer及consumer会根据zookeeper上的watcher感知这些变化,并及时作出调整
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
二、安装zookeeper,并配置集群
准备三台机器做集群
服务器 | IP地址 | 端口 |
服务器1 | 172.16.0.41 | 2181/2881/3881 |
服务器2 | 172.16.0.42 | 2182/2882/3882 |
服务器3 | 172.16.0.43 | 2183/2883/3883 |
2.1配置java环境
将jdk-7u79-linux-x64上传到三台服务器安装配置。
给三台服务器分别创建java文件夹。
将jdk 放到java文件夹下并解压,然后删掉压缩文件。
配置jdk全局变量。
#vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.7.0_79
export JRE_HOME=/usr/local/java/jdk1.7.0_79/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
2.2 修改操作系统的/etc/hosts文件,添加IP与主机名映射:
# zookeeper cluster servers
172.16.0.41 edu-zk-01
172.16.0.42 edu-zk-02
172.16.0.43 edu-zk-03
2.3下载zookeeper-3.4.7.tar.gz 到/home/zy/zookeeper目录
# mkdir -p /usr/local/zookeeper
# cd / usr/local/zookeeper/
# wget http://apache.fayea.com/zookeeper/zookeeper-3.4.7/zookeeper-3.4.7.tar.gz
2.4 解压zookeeper安装包,并对节点重民名
#tar -zxvf zookeeper-3.4.7.tar.gz
服务器1:
#mv zookeeper-3.4.7 node-01
服务器2: #mv zookeeper-3.4.7 node-02
服务器3:
#mv zookeeper-3.4.7 node-03
2.5 在zookeeper的各个节点下 创建数据和日志目录
#cd /usr/local/zookeeper
#mkdir data
#mkdir logs
2.6 重命名配置文件
将zookeeper/node-0X/conf目录下的zoo_sample.cfg文件拷贝一份,命名为zoo.cfg:
#cp zoo_sample.cfg zoo.cfg
2.7 修改zoo.cfg 配置文件
三台服务器做同样配置:zookeeper/node-01的配置(/usr/local/zookeeper/node-01/conf/zoo.cfg)如下:
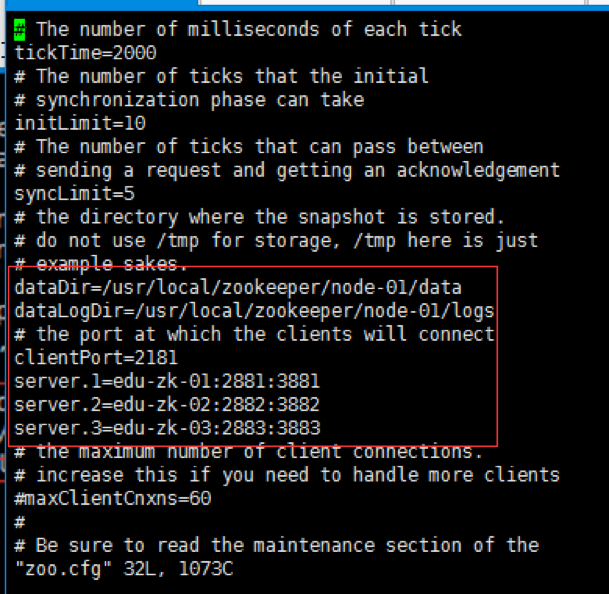
参数说明:
tickTime=2000
tickTime这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳。
initLimit=10
initLimit这个配置项是用来配置Zookeeper接受客户端(这里所说的客户端不是用户连接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到Leader的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
syncLimit=5
syncLimit这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir=/usr/local/zookeeper/node-01/data
dataDir顾名思义就是Zookeeper保存数据的目录,默认情况下Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort=2181
clientPort这个端口就是客户端(应用程序)连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求。
server.A=B:C:D
server.1=edu-zk-01:2881:3881
server.2=edu-zk-02:2882:3882
server.3=edu-zk-03:2883:3883
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址(或者是与IP地址做了映射的主机名);
C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的Leader服务器交换信息的端口;
D是在leader挂掉时专门用来进行选举leader所用的端口。
注意:如果是伪集群的配置方式,不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
2.8 创建myid文件
在dataDir=/usr/local/zookeeper/node-0X/data 下创建myid文件
编辑myid文件,并在对应的IP的机器上输入对应的编号。如在node-01上,myid文件内容就是1,node-02上就是2,node-03上就是3:
#vi /usr/local/zookeeper/node-01/data/myid## 值为1
#vi /usr/local/zookeeper/node-02/data/myid## 值为2
#vi /usr/local/zookeeper/node-03/data/myid## 值为3
2.9 启动测试zookeeper
(1)进入/usr/local/zookeeper/node-0X/bin目录下执行:
#/usr/local/zookeeper/node-01/bin/zkServer.sh start
#/usr/local/zookeeper/node-02/bin/zkServer.sh start
#/usr/local/zookeeper/node-03/bin/zkServer.sh start

(2)输入jps命令查看进程:

其中,QuorumPeerMain是zookeeper进程,说明启动正常
(3)查看状态:
# /usr/local/zookeeper/node-01/bin/zkServer.sh status

(4)查看zookeeper服务输出信息:
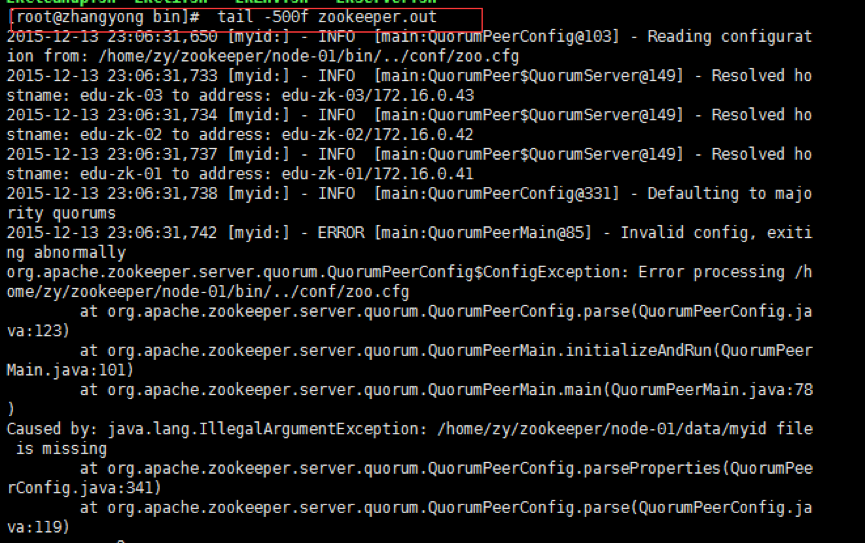
由于服务信息输出文件在/usr/local/zookeeper/node-0X/bin/zookeeper.out
$ tail -500f zookeeper.out
三、KAFKA集群配置
利用安装zookeeper的三台服务器做KAFKA集群,也可以新建三个虚拟机去操作。
服务器 | IP地址 | 端口 |
服务器1 | 172.16.0.41 | 9092 |
服务器2 | 172.16.0.42 | 9092 |
服务器3 | 172.16.0.43 | 9092 |
4.1 下载 kafka_2.9.2-0.8.1
分别在三台服务器创建kafka目录并且下载kafka压缩包
#mkdir /usr/local/kafka
#tar –zxvf kafka_2.9.2-0.8.1.tar.gz
4.2 创建log文件夹
#mkdir /usr/local/kafka/kafkalogs
4.3 配置kafka
#cd /usr/local/kafka/kafka_2.9.2-0.8.1/config
#vi server.properties 修改项如下:
broker.id=0 //当前机器在集群中的唯一标识
port=9092 //kafka对外提供服务的tcp端口
host.name=172.16.0.41 //主机IP地址
log.dirs=/usr/local/kafka/kafkalogs //log存放目录
message.max.byte=5048576 //kafka一条消息容纳的消息最大为多少
default.replication.factor=2 //每个分区默认副本数量
replica.fetch.max.bytes=5048576
zookeeper.connect=172.16.0.41:2181,172.16.0.42:2182,172.16.0.43:2183
4.4 启动kafka
# ./kafka-server-start.sh -daemon ../config/server.properties //后台启动运行
4.5 问题解决
[root@master ~]# /export/kafka/bin/kafka-console-producer.sh --broker-list 10.14.2.201:9092,10.14.2.202:9092,10.14.2.203:9092,10.14.2.204:9092 --topic test
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
# /export/kafka/bin/kafka-console-consumer.sh --zookeeper 10.14.2.201:2181,10.14.2.202:2181,10.14.2.203:2181,10.14.2.204:2181 --topic test --from-beginning
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
解决方法:
下载slf4j-1.7.6.zip
http://www.slf4j.org/dist/slf4j-1.7.6.zip
解压
unzip slf4j-1.7.6.zip
把slf4j-nop-1.7.6.jar 包复制到kafka libs目录下面
cd slf4j-1.7.6
cp slf4j-nop-1.7.6.jar /export/kafka/libs/
四、KAFKA集群验证
5.1 创建topic
#./kafka-topics.sh --create --zookeeper 172.16.0.42:2182 --replication-factor 1 --partitions 1 --topic test
5.2 查看topic
# ./kafka-topics.sh --list --zookeeper 172.16.0.42:2182
5.3 开启发送者并发送消息
#./kafka-console-producer.sh --broker-list 172.16.0.41:9092 --topic test
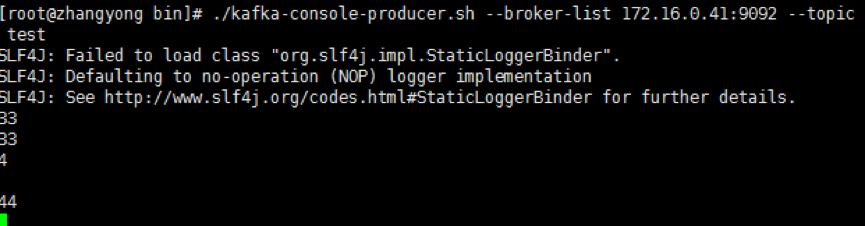
5.4 开启消费者并接收消息
#./kafka-console-consumer.sh --zookeeper 172.16.0.42:2182 --topic test --from-beginning
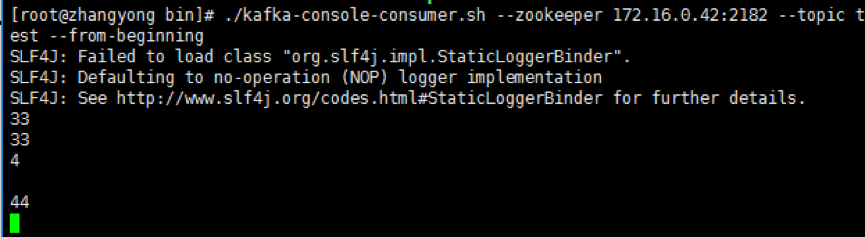
更参考内容:http://www.roncoo.com/article/index.html?title=%E6%9E%B6%E6%9E%84%E5%B8%88%E4%B9%8B%E8%B7%AF


更多建议: