
 免费 AI IDE
免费 AI IDE

Solr结果集群
Solr 集群(或集群分析)插件尝试自动发现相关的搜索命中(文档)组,并将可读的标签分配给这些组。
默认情况下,在 Solr 中,集群算法被应用于每个查询的搜索结果 - 这被称为在线集群。虽然 Solr 包含全索引集群(离线集群)的扩展,但本节将重点讨论在线集群。
为给定查询发现的集群可以视为动态方面。如果定期分析比较困难(字段值不是事先知道的),或者查询在本质上是探索性的,这是有利的。查看 Carrot2 项目的演示页面,查看搜索结果集群的实例(可视化中的组在右侧搜索结果中自动发现,没有涉及外部信息)。
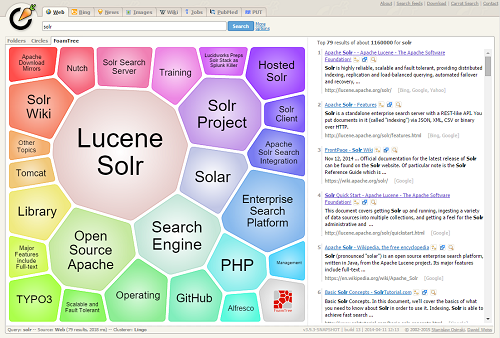
发给系统的查询是 Solr。显然,分面不能产生一组类似的组,尽管这两种技术的目标是相似的 - 让用户浏览一组搜索结果,并重新调整查询或将焦点缩小到当前文档的一个子集。集群也类似于结果分组,因为它可以帮助更深入地查看搜索结果,超出前几个点击率。
集群概念
传递给集群组件的每个文档都由几个逻辑部分组成:
- 唯一的标识符
- 起源 URL
- 标题
- 主要内容
- 标题和内容的语言代码
标识符部分是必须的,其他所有部分都是可选的,但至少需要一个文本字段(标题或内容)来使集群过程合理。重要的是要记住,逻辑文档部分必须映射到特定的架构及其字段。集群的内容(文本)可以来自存储的文本字段或使用高亮过滤的上下文,所有这些选项将在配置部分进行说明。
一个集群算法是,在搜索结果中发现文档之间的关系,并且形成可读的集群标签的实际逻辑 (实现)。根据算法的选择,集群可能会变化。Solr 提供了几个在开源 Carrot2 项目中实现的算法,也有商业替代方案。
集群快速入门示例
Solr 附带的 “techproducts” 示例已预先配置了所有必要的结果集群组件,但默认情况下它们是禁用的。
要启用集群组件 contrib 和配置为使用它的专用搜索处理程序,请在运行示例时指定 JVM 系统属性:
bin/solr start -e techproducts -Dsolr.clustering.enabled=true您现在可以通过在浏览器中打开以下 URL 来尝试集群处理程序:
http://localhost:8983/solr/techproducts/clustering?q=:&rows=100输出 XML 应包括搜索匹配和最后自动发现的集群的数组,类似于此处显示的输出:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">299</int>
</lst>
<result name="response" numFound="32" start="0" maxScore="1.0">
<doc>
<str name="id">GB18030TEST</str>
<str name="name">Test with some GB18030 encoded characters</str>
<arr name="features">
<str>No accents here</str>
<str>这是一个功能</str>
<str>This is a feature (translated)</str>
<str>这份文件是很有光泽</str>
<str>This document is very shiny (translated)</str>
</arr>
<float name="price">0.0</float>
<str name="price_c">0,USD</str>
<bool name="inStock">true</bool>
<long name="_version_">1448955395025403904</long>
<float name="score">1.0</float>
</doc>
<!-- more search hits, omitted -->
</result>
<arr name="clusters">
<lst>
<arr name="labels">
<str>DDR</str>
</arr>
<double name="score">3.9599865057283354</double>
<arr name="docs">
<str>TWINX2048-3200PRO</str>
<str>VS1GB400C3</str>
<str>VDBDB1A16</str>
</arr>
</lst>
<lst>
<arr name="labels">
<str>iPod</str>
</arr>
<double name="score">11.959228467119022</double>
<arr name="docs">
<str>F8V7067-APL-KIT</str>
<str>IW-02</str>
<str>MA147LL/A</str>
</arr>
</lst>
<!-- More clusters here, omitted. -->
<lst>
<arr name="labels">
<str>Other Topics</str>
</arr>
<double name="score">0.0</double>
<bool name="other-topics">true</bool>
<arr name="docs">
<str>adata</str>
<str>apple</str>
<str>asus</str>
<str>ati</str>
<!-- other unassigned document IDs here -->
</arr>
</lst>
</arr>
</response>这个查询(*:*)发现了几个集群,将搜索命中分为各种类别:DDR、iPod、硬盘驱动器等。每个集群都有一个标签和分数,表示集群的“优点”。分数是特定于算法的,并且仅在与同一集合中的其他集群的分数相关时才是有意义的。换言之,如果集群 A 比集群 B 具有更高的分数,则集群 A 应该具有更好的质量(具有更好的标签和更连贯的文档集)。每个群集都有一组属于它的文档的标识符数组。这些标识符对应于架构中声明的 uniqueKey 字段。
根据输入文档的质量,一些集群可能没有多大意义。有些文件可能被排除在外,根本就不会被集群;这些将被分配到合成的其他主题组,标记的 other-topics 属性设置为 true(请参阅上面的XML 转储为例)。其他主题组的分数为零。
安装集群 Contrib
集群 contrib 扩展需要 dist/solr-clustering-*.jar 和所有 contrib/clustering/lib 下的 JAR。
集群配置
集群搜索组件和请求处理程序的声明
集群扩展是一个搜索组件,必须在 solrconfig.xml 中声明。这样一个组件可以作为链中的最后一个组件添加到请求处理程序中(因为它需要搜索结果,这些搜索结果必须先被搜索组件提取)。
示例配置可能如下所示:
- 包括所需的 contrib JAR。请注意,默认路径是相对于 Solr 核心的,所以他们可能需要调整您的配置,或明确的规格:$solr.install.dir。
<lib dir="${solr.install.dir:../../..}/contrib/clustering/lib/" regex=".*\.jar" /> <lib dir="${solr.install.dir:../../..}/dist/" regex="solr-clustering-\d.*\.jar" /> - 搜索组件的声明。每个组件还可以声明多个集群管道,可以通过传递 clustering.engine=(engine name)URL 参数在运行时选择它们。
<searchComponent name="clustering" class="solr.clustering.ClusteringComponent"> <!-- Lingo clustering algorithm --> <lst name="engine"> <str name="name">lingo</str> <str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str> </lst> <!-- An example definition for the STC clustering algorithm. --> <lst name="engine"> <str name="name">stc</str> <str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str> </lst> </searchComponent> - 一个请求处理程序,我们使用它附加上面声明的集群组件。
<requestHandler name="/clustering" class="solr.SearchHandler"> <lst name="defaults"> <bool name="clustering">true</bool> <bool name="clustering.results">true</bool> <!-- Logical field to physical field mapping. --> <str name="carrot.url">id</str> <str name="carrot.title">doctitle</str> <str name="carrot.snippet">content</str> <!-- Configure any other request handler parameters. We will cluster the top 100 search results so bump up the 'rows' parameter. --> <str name="rows">100</str> <str name="fl">*,score</str> </lst> <!-- Append clustering at the end of the list of search components. --> <arr name="last-components"> <str>clustering</str> </arr> </requestHandler>
集群组件的配置参数
以下每个集群工具或整个集群组件(取决于它们在哪里声明)的下列参数都可用:
- clustering 参数
当值为
true,表示集群组件已启用。 - clustering.engine 参数
声明使用哪个集群工具。如果不存在,则首先声明将成为默认工具的工具。
- clustering.results 参数
当为
true时,该组件将执行搜索结果的集群(这应该被启用)。 - clustering.collection 参数
当为
true时,该组件将执行整个文档索引的集群(本节不包括全索引集群)。
在工具声明级别,支持以下参数:
- carrot.algorithm 参数
算法类。
- carrot.resourcesDir 参数
特定于算法的资源和配置文件(停用词、其他词汇资源、默认设置)。默认指向
conf/clustering/carrot2/ - carrot.outputSubClusters 参数
如果为
true算法支持分级集群,子集群也将被发射。默认值:true。 - carrot.numDescriptions 参数
返回的每个集群标签的最大数量(如果该算法将多个标签分配给集群)。
该 carrot.algorithm 参数应包含由 Carrot2 框架所支持的算法的完全限定类名。目前,以下算法可用:
- org.carrot2.clustering.lingo.LingoClusteringAlgorithm (开源)
- org.carrot2.clustering.stc.STCClusteringAlgorithm (开源)
- org.carrot2.clustering.kmeans.BisectingKMeansClusteringAlgorithm (开源)
- com.carrotsearch.lingo3g.Lingo3GClusteringAlgorithm (商业)
有关这些算法的特性比较,请参阅以下链接:
- http://doc.carrot2.org/#section.advanced-topics.fine-tuning.choosing-algorithm
- http://project.carrot2.org/algorithms.html
- http://carrotsearch.com/lingo3g-comparison.html
选择哪种算法取决于流量(STC 比 Lingo 快,但可以说产生的直观性较差,Lingo3G 是最快的算法,但不是免费的或开源的)、预期的结果(Lingo3G 提供了分层集群,Lingo 和 STC 提供不分层次的集群),以及输入数据(每个算法将稍微不同地将输入进行集群)。没有人知道哪种算法是“最好的”。
上下文和全字段集群
集群工具可以将集群应用于(已存储的)字段的全部内容,或者可以在集群之前运行内部高亮度传递来提取上下文片段。如果逻辑代码段字段包含大量内容(这会影响集群性能),建议使用高亮显示。高亮显示还可以提高集群的质量,因为传递给算法的内容将更关注于查询(这将是查询特定的上下文)。以下参数控制内部高亮。
- carrot.produceSummary 参数
当为
true时,集群组件将对指向carrot.title和carrot.snippet的逻辑字段的内容上运行高亮传递。否则,这些字段的全部内容将被聚集。 - carrot.fragSize 参数
由高亮创建的片段的大小(以字符为符号)。如果没有指定,将使用默认的高亮 fragsize(
hl.fragsize)。 - carrot.summarySnippets 参数
要为集群生成的摘要片段的数量。如果未指定,则将使用默认突出显示片段计数(
hl.snippets)。
文档字段映射的逻辑
正如“集群概念”中已经提到的那样,集群组件对由需要映射到存储在 Solr 中的数据的物理架构的由逻辑部分组成的“文档”进行集群。字段映射属性提供字段和逻辑文档部分之间的连接。请注意,title 和 snippet 字段的内容必须存储,以便在搜索时可以检索到它。
- carrot.title 参数
应该映射到逻辑文档标题的字段(或者以逗号或空格分隔的字段列表)。与内容(片段)相比,集群算法通常对标题字段的内容给予更重的权重。为获得最佳效果,该字段应包含简洁、无噪音的内容。如果数据中没有明确的标题,则可以将此参数留空。
- carrot.snippet 参数
应该映射到逻辑文档的主要内容的字段(或以逗号或空格分隔的字段列表)。如果此映射指向非常大的内容字段,则集群的性能可能会显着下降。另一种方法是使用查询上下文片段来进行集群,而不是使用完整的字段内容。您可以参阅
carrot.produceSummary参数说明来获取更加详细的信息。 - carrot.url 参数
应该映射到逻辑文档的内容URL的字段。如果不需要,留空白。
集群多语言内容
字段映射规范可以包含一个 carrot.lang 参数,该参数定义存储写入文档的标题和内容的语言的 ISO 639-1 代码的字段。这个信息可以基于对文档来源的先验知识或者在索引时间应用的语言检测过滤器而被存储在索引中。Carrot2
框架内的所有算法都将接受在 LanguageCode 枚举中定义的语言的 ISO 代码。
语言提示使集群算法可以更轻松地在输入中分隔来自不同语言的文档,并为集群选择正确的语言资源。如果您确实有多语言查询结果(或以不同于英语的语言查询结果),强烈建议适当地映射语言字段。
- carrot.lang
存储文档的文本字段的语言的 ISO 639-1 代码的字段。
- carrot.lcmap
任意字符串映射到由
carrot.lang使用的 ISO 639 双字母代码。该参数的语法与langid.map.lcmap相同,比如:langid.map.lcmap=japanese:ja polish:pl english:en
默认语言也可以使用 Carrot2 特定的算法属性(在本例中为 MultilingualClustering.defaultLanguage 属性)进行设置。
调整算法设置
Solr 附带的算法正在使用它们的默认设置,这对于所有的数据集都是不够的。所有算法都有词汇资源和资源(停用词,词干,参数),可能需要调整以获得更好的集群(和集群标签)。对于基于 Carrot2 的算法,最好参考一个名为 Carrot2 Workbench(截图如下)的专用调试应用程序。从这个应用程序中,您可以将一组算法属性导出为一个 XML 文件,然后将其放置在由carrot.resourcesDir 指向的位置下。
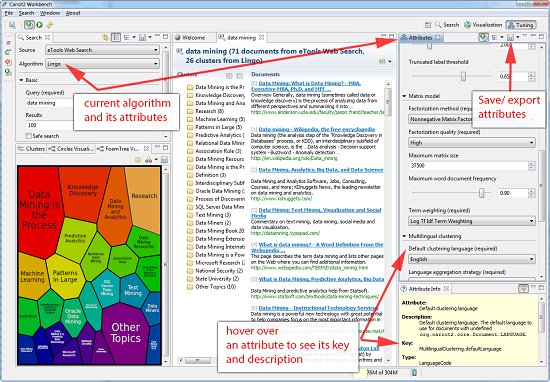
为集群提供默认值
在集群组件中声明的所有引擎(算法)的默认属性都放置在 carrot.resourcesDir 下,并具有预期的文件名:engineName-attributes.xml。因此,对于一个名为 lingo 的引擎和默认值carrot.resourcesDir,这些属性会从 conf/clustering/carrot2/lingo-attributes.xml 的文件中读取。
下面显示了将文档的默认语言更改为波兰语的示例 XML 文件。
<attribute-sets default="attributes">
<attribute-set id="attributes">
<value-set>
<label>attributes</label>
<attribute key="MultilingualClustering.defaultLanguage">
<value type="org.carrot2.core.LanguageCode" value="POLISH"/>
</attribute>
</value-set>
</attribute-set>
</attribute-sets>在查询时调整算法
集群组件和 Carrot2 集群算法可以接受查询时间属性覆盖。请注意,某些事情(例如词汇资源)只能初始化一次(在启动时,通过 XML 配置文件)。
为 Lingo 算法更改 LingoClusteringAlgorithm.desiredClusterCountBaseLingo 参数的示例查询:
http://localhost:8983/solr/techproducts/clustering?q=:&rows=100&LingoClusteringAlgorithm.desiredClusterCountBase = 20集群引擎(solrconfig.xml 声明的算法)也可以在运行时通过传递 clustering.engine=namerequest 属性来改变:
http://localhost:8983/solr/techproducts/clustering?q=:&rows=100&clustering.engine=kmeans有关动态集群的性能注意事项
搜索结果的动态集群有两个主要的性能损失:
- 获取大于平常数量的搜索结果(50、100或更多文档)的成本增加
- 集群本身的额外计算成本。
对于简单的查询,集群时间通常会占据获取时间。如果文档内容很长,则存储内容的检索可能成为瓶颈。可以通过以下几种方式降低集群的性能影响:
- 通过启用 carrot.produceSummary 属性,将较少的内容反馈给集群算法。
- 对所选字段(仅标题)执行集群,使输入变小。
- 使用更快的算法(STC 代替 Lingo,Lingo3G 代替 STC),
- 调整与特定算法直接相关的性能属性。
其中一些技术在 Apache SOLR 和 Carrot2 集成策略文档中进行了描述,可在:http://carrot2.github.io/solr-integration-strategies 上找到。Carrot2 手册中还包含了提高性能的主题,网址为:http://doc.carrot2.org/#section.advanced-topics.fine-tuning.performance。
其他资源
以下资源提供了有关 Solr 中的集群组件及其潜在应用程序的其他信息。


更多建议: