
 免费 AI IDE
免费 AI IDE

impala 架构
Impala是在Hadoop集群中的许多系统上运行的MPP(大规模并行处理)查询执行引擎。 与传统存储系统不同,impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore和Impala元数据或metastore。
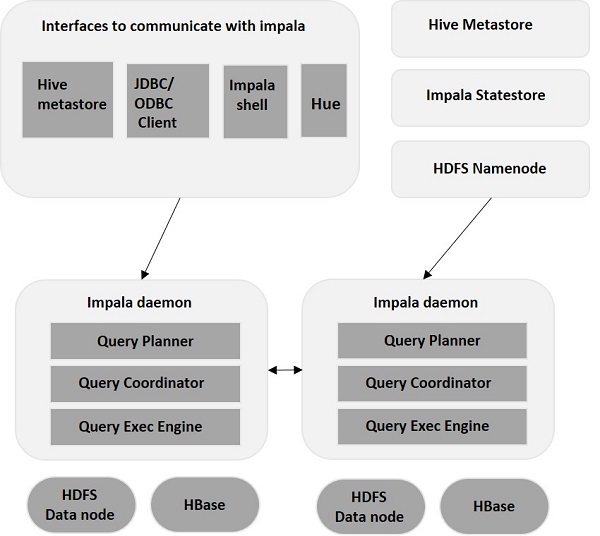
Impala daemon(Impalad)
Impala daemon(也称为impalad)在安装Impala的每个节点上运行。 它接受来自各种接口的查询,如impala shell,hue browser等...并处理它们。
每当将查询提交到特定节点上的impalad时,该节点充当该查询的“协调器节点”。 Impalad还在其他节点上运行多个查询。 接受查询后,Impalad读取和写入数据文件,并通过将工作分发到Impala集群中的其他Impala节点来并行化查询。 当查询处理各种Impalad实例时,所有查询都将结果返回到中央协调节点。
根据需要,可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad。
Impala 存储的状态
Impala有另一个称为Impala State存储的重要组件,它负责检查每个Impalad的运行状况,然后经常将每个Impala Daemon运行状况中继给其他守护程序。 这可以在运行Impala服务器或群集中的其他节点的同一节点上运行。Impala State存储守护进程的名称为存储的状态。 Impalad将其运行状况报告给Impala State存储守护程序,即存储的状态。
在由于任何原因导致节点故障的情况下,Statestore将更新所有其他节点关于此故障,并且一旦此类通知可用于其他impalad,则其他Impala守护程序不会向受影响的节点分配任何进一步的查询。
Impala元数据和元存储
Impala元数据和元存储是另一个重要组件。 Impala使用传统的MySQL或PostgreSQL数据库来存储表定义。 诸如表和列信息和表定义的重要细节存储在称为元存储的集中式数据库中。
每个Impala节点在本地缓存所有元数据。 当处理极大量的数据和/或许多分区时,获得表特定的元数据可能需要大量的时间。 因此,本地存储的元数据缓存有助于立即提供这样的信息。
当表定义或表数据更新时,其他Impala后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
查询处理接口
要处理查询,Impala提供了三个接口,如下所示。
Impala-shell - 使用Cloudera VM设置Impala后,可以通过在编辑器中键入impala-shell命令来启动Impala shell。 我们将在后续章节中更多地讨论Impala shell。
Hue界面 - 您可以使用Hue浏览器处理Impala查询。 在Hue浏览器中,您有Impala查询编辑器,您可以在其中键入和执行impala查询。 要访问此编辑器,首先,您需要登录到Hue浏览器。
ODBC / JDBC驱动程序 - 与其他数据库一样,Impala提供ODBC / JDBC驱动程序。 使用这些驱动程序,您可以通过支持这些驱动程序的编程语言连接到impala,并构建使用这些编程语言在impala中处理查询的应用程序。
查询执行过程
每当用户使用提供的任何接口传递查询时,集群中的Impalads之一就会接受该查询。 此Impalad被视为该特定查询的协调程序。在接收到查询后,查询协调器使用Hive元存储中的表模式验证查询是否合适。 稍后,它从HDFS名称节点收集关于执行查询所需的数据的位置的信息,并将该信息发送到其他impalad以便执行查询。
所有其他Impala守护程序读取指定的数据块并处理查询。 一旦所有守护程序完成其任务,查询协调器将收集结果并将其传递给用户。


更多建议: