
 免费 AI IDE
免费 AI IDE

Hadoop YARN
旧的MapReduce架构

- JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker: 加载或关闭任务,定时报告任务状态
此架构会有以下问题:
- JobTracker 是 MapReduce 的集中处理点,存在单点故障
- JobTracker 完成了太多的任务,造成了过多的资源消耗,当 MapReduce job 非常多的时候,会造成很大的内存开销。这也是业界普遍总结出老 Hadoop 的 MapReduce 只能支持 4000 节点主机的上限
- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM
- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot , 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就集群资源利用的问题
总的来说就是单点问题和资源利用率问题
YARN架构
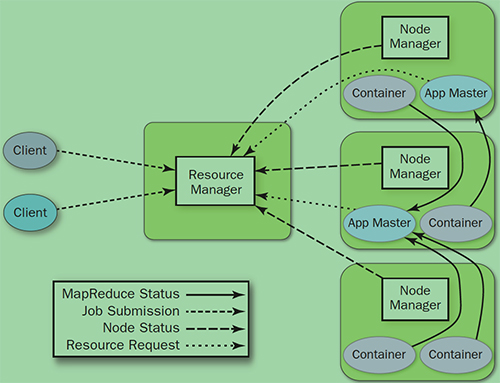
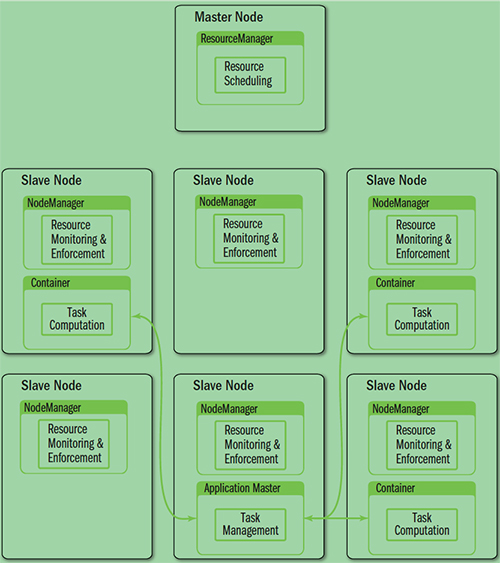
YARN就是将 JobTracker 的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个每个作业的管理(ApplicationMaster) ResourceManager 和 NodeManager 提供了计算资源的分配和管理,而 ApplicationMaster 则完成应用程序的运行
- ResourceManager: 全局资源管理和任务调度
- NodeManager: 单个节点的资源管理和监控
- ApplicationMaster: 单个作业的资源管理和任务监控
- Container: 资源申请的单位和任务运行的容器
架构对比
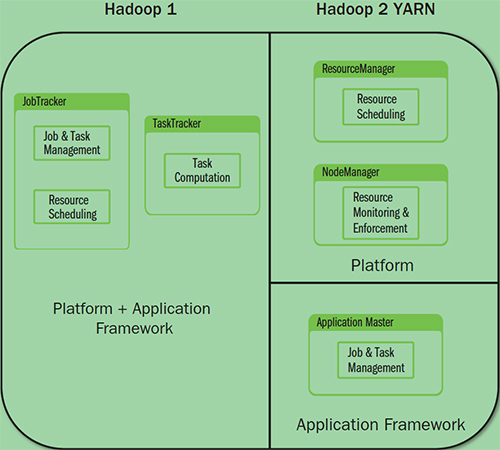
YARN架构下形成了一个通用的资源管理平台和一个通用的应用计算平台,避免了旧架构的单点问题和资源利用率问题,同时也让在其上运行的应用不再局限于 MapReduce 形式
YARN基本流程
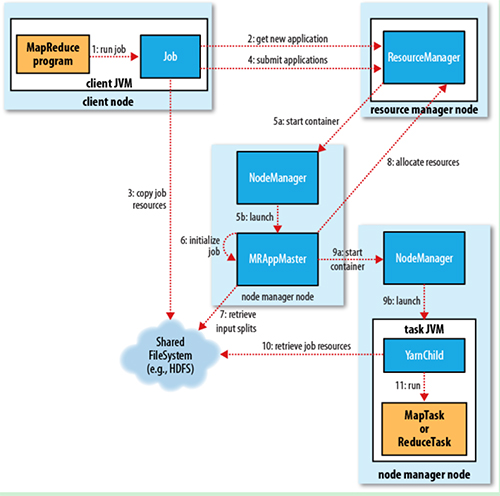

1. Job submission
从ResourceManager 中获取一个Application ID 检查作业输出配置,计算输入分片 拷贝作业资源(job jar、配置文件、分片信息)到 HDFS,以便后面任务的执行
2. Job initialization
ResourceManager 将作业递交给 Scheduler(有很多调度算法,一般是根据优先级)Scheduler 为作业分配一个 Container,ResourceManager 就加载一个 application master process 并交给 NodeManager。
管理 ApplicationMaster 主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个 Map task 和相应的 reduce task Application Master 还决定如何运行作业,如果作业很小(可配置),则直接在同一个 JVM 下运行
3. Task assignment
ApplicationMaster 向 Resource Manager 申请资源(一个个的Container,指定任务分配的资源要求)一般是根据 data locality 来分配资源
4. Task execution
ApplicationMaster 根据 ResourceManager 的分配情况,在对应的 NodeManager 中启动 Container 从 HDFS 中读取任务所需资源(job jar,配置文件等),然后执行该任务
5. Progress and status update
定时将任务的进度和状态报告给 ApplicationMaster Client 定时向 ApplicationMaster 获取整个任务的进度和状态
6. Job completion
Client定时检查整个作业是否完成 作业完成后,会清空临时文件、目录等


更多建议: