


OpenCV矩阵上的掩码操作
矩阵上的掩码操作非常简单。这个想法是,我们根据掩码矩阵(也称为内核)重新计算图像中的每个像素值。该掩码保存将调整相邻像素(和当前像素)对新像素值有多大影响的值。从数学的角度来看,我们用加权平均值与我们指定的值进行比较。
我们的测试案例
C++
让我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或使用cv :: filter2D函数来实现这一点。
基本方法
这里有一个功能:
void Sharpen(const Mat& myImage,Mat& Result)
{
CV_Assert(myImage.depth() == CV_8U); // accept only uchar images
const int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());
for(int j = 1 ; j < myImage.rows-1; ++j)
{
const uchar* previous = myImage.ptr<uchar>(j - 1);
const uchar* current = myImage.ptr<uchar>(j );
const uchar* next = myImage.ptr<uchar>(j + 1);
uchar* output = Result.ptr<uchar>(j);
for(int i= nChannels;i < nChannels*(myImage.cols-1); ++i)
{
*output++ = saturate_cast<uchar>(5*current[i]
-current[i-nChannels] - current[i+nChannels] - previous[i] - next[i]);
}
}
Result.row(0).setTo(Scalar(0));
Result.row(Result.rows-1).setTo(Scalar(0));
Result.col(0).setTo(Scalar(0));
Result.col(Result.cols-1).setTo(Scalar(0));
}首先我们确保输入图像数据是unsigned char格式。为此,我们使用cv :: CV_Assert函数,当其中的表达式为false时,该函数会引发错误。
CV_Assert(myImage.depth() == CV_8U); // accept only uchar images
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
我们将通过指针迭代它们,因此元素的总数取决于这个数字。
const int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());我们将使用普通C []运算符来访问像素。因为我们需要在同一时间访问多行,我们将获取每个行的指针(前一个,当前和下一行)。我们需要另一个指向我们要保存计算的指针。然后只需使用[]运算符访问正确的项目。为了在前面移动输出指针,我们在每个操作之后简单地增加一个(一个字节):
for(int j = 1; j <myImage.rows-1; ++ j)
{
const uchar * previous = myImage.ptr < uchar >(j - 1);
const uchar * current = myImage.ptr < uchar >(j);
const uchar * next = myImage.ptr < uchar >(j + 1);
uchar * output = Result.ptr < uchar >(j);
for(int i = nChannels; i <nChannels *(myImage.cols-1); ++ i)
{
* output ++ = saturate_cast < uchar >(5 * current [i]
-current [i-nChannels] - current [i + nChannels] - 上一个[i] - next [i]);
}
}在图像的边框上,上面的符号会导致像素位置不一致(如减去一个减去一个)。在这些点上,我们的公式是未定义的。一个简单的解决方案是在这些点上不应用内核,例如,将边框上的像素设置为零:
Result.row(0).setTo(Scalar(0));
Result.row(Result.rows-1).setTo(Scalar(0));
Result.col(0).setTo(Scalar(0));
Result.col(Result.cols-1).setTo(Scalar(0));filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
Mat kernel = (Mat_<char>(3,3) << 0, -1, 0,
-1, 5, -1,
0, -1, 0);然后调用cv :: filter2D函数,指定输入,输出图像和内核使用:
filter2D(src,dst1,src.depth(),kernel);
该函数甚至有第五个可选参数来指定内核的中心,第六个可选参数,用于在将其存储在K中之前添加可选值,然后将其存储在K中,第七个用于确定在操作未定义的区域中要执行的操作(国界)。
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:
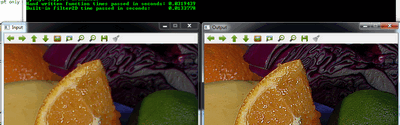
您可以从这里下载此源代码,或查看OpenCV源代码库示例目录samples/cpp/tutorial_code/core/mat_mask_operations/mat_mask_operations.cpp。
Java
让我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或者使用Imgproc.filter2D()函数来实现这一点。
基本方法
这里有一个功能:
public static double saturate(double x) {
return x > 255.0 ? 255.0 : (x < 0.0 ? 0.0 : x);
}
public Mat sharpen(Mat myImage, Mat Result) {
myImage.convertTo(myImage, CvType.CV_8U);
int nChannels = myImage.channels();
Result.create(myImage.size(), myImage.type());
for (int j = 1; j < myImage.rows() - 1; ++j) {
for (int i = 1; i < myImage.cols() - 1; ++i) {
double sum[] = new double[nChannels];
for (int k = 0; k < nChannels; ++k) {
double top = -myImage.get(j - 1, i)[k];
double bottom = -myImage.get(j + 1, i)[k];
double center = (5 * myImage.get(j, i)[k]);
double left = -myImage.get(j, i - 1)[k];
double right = -myImage.get(j, i + 1)[k];
sum[k] = saturate(top + bottom + center + left + right);
}
Result.put(j, i, sum);
}
}
Result.row(0).setTo(new Scalar(0));
Result.row(Result.rows() - 1).setTo(new Scalar(0));
Result.col(0).setTo(new Scalar(0));
Result.col(Result.cols() - 1).setTo(new Scalar(0));
return Result;
}首先我们确保输入图像数据以无符号8位格式。
myImage.convertTo(myImage,CvType .CV_8U);
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());我们需要访问多个行和列,可以通过向当前中心(i,j)添加或减去1来完成。然后我们应用总和并将新值放在结果矩阵中。
for(int j = 1; j <myImage.rows() - 1; ++ j){
for(int i = 1; i <myImage.cols() - 1; ++ i){
double sum [] = new double [nChannels];
for(int k = 0; k <nChannels; ++ k){
double top = -myImage.get(j - 1,i)[k];
double bottom = -myImage.get(j + 1,i)[k];
double center =(5 * myImage.get(j,i)[k]);
double left = -myImage.get(j,i-1)[k];
double right = -myImage.get(j,i + 1)[k];
sum [k] =饱和(顶+底+中+左+右);
}
Result.put(j,i,sum);
}
}在图像的边框上,上面的符号会导致像素位置不存在(如(-1,-1))。在这些点上,我们的公式是未定义的。一个简单的解决方案是在这些点上不应用内核,例如,将边框上的像素设置为零:
Result.row(0).setTo(new Scalar(0));
Result.row(Result.rows() - 1).setTo(new Scalar(0));
Result.col(0).setTo(new Scalar(0));
Result.col(Result.cols() - 1).setTo(new Scalar(0));filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
Mat kern = new Mat(3,3,CvType .CV_8S);
int row = 0,col = 0;
kern.put(row,col,0,-1,0,-1,5,-1,0,-1,0);然后调用Imgproc.filter2D()函数,指定要使用的输入,输出图像和内核:
Imgproc.filter2D(src,dst1,src.depth(),kern);
该函数甚至有第五个可选参数来指定内核的中心,第六个可选参数,用于在将其存储在K中之前添加可选值,然后将其存储在K中,第七个用于确定在操作未定义的区域中要执行的操作(国界)。
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:

您可以在OpenCV源代码库示例目录中查看samples/java/tutorial_code/core/mat_mask_operations/MatMaskOperations.java。
Python
我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或使用cv2.filter2D()函数来实现这一点。
基本方法
这里有一个功能:
def is_grayscale(my_image):
return len(my_image.shape) < 3
def saturated(sum_value):
if sum_value > 255:
sum_value = 255
if sum_value < 0:
sum_value = 0
return sum_value
def sharpen(my_image):
if is_grayscale(my_image):
height, width = my_image.shape
else:
my_image = cv2.cvtColor(my_image, cv2.CV_8U)
height, width, n_channels = my_image.shape
result = np.zeros(my_image.shape, my_image.dtype)
for j in range(1, height - 1):
for i in range(1, width - 1):
if is_grayscale(my_image):
sum_value = 5 * my_image[j, i] - my_image[j + 1, i] - my_image[j - 1, i] \
- my_image[j, i + 1] - my_image[j, i - 1]
result[j, i] = saturated(sum_value)
else:
for k in range(0, n_channels):
sum_value = 5 * my_image[j, i, k] - my_image[j + 1, i, k] - my_image[j - 1, i, k] \
- my_image[j, i + 1, k] - my_image[j, i - 1, k]
result[j, i, k] = saturated(sum_value)
return result首先我们确保输入图像数据以无符号8位格式。
my_image = cv2.cvtColor(my_image,cv2.CV_8U)
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
height,width,n_channels = my_image.shape
result = np.zeros(my_image.shape,my_image.dtype)我们需要访问多个行和列,可以通过向当前中心(i,j)添加或减去1来完成。然后我们应用总和并将新值放在结果矩阵中。
for j in range(1, height - 1):
for i in range(1, width - 1):
if is_grayscale(my_image):
sum_value = 5 * my_image[j, i] - my_image[j + 1, i] - my_image[j - 1, i] \
- my_image[j, i + 1] - my_image[j, i - 1]
result[j, i] = saturated(sum_value)
else:
for k in range(0, n_channels):
sum_value = 5 * my_image[j, i, k] - my_image[j + 1, i, k] - my_image[j - 1, i, k] \
- my_image[j, i + 1, k] - my_image[j, i - 1, k]
result[j, i, k] = saturated(sum_value)The filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
kernel = np.array([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]], np.float32) # kernel should be floating point type然后调用cv2.filter2D()函数,指定要使用的输入,输出图像和kernell:
dst1 = cv2.filter2D(src, -1, kernel) # ddepth = -1, means destination image has depth same as input image
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:
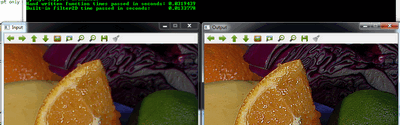
您可以在OpenCV源代码库示例目录中查看samples/python/tutorial_code/core/mat_mask_operations/mat_mask_operations.py。

更多建议: