
 免费 AI IDE
免费 AI IDE

集合
Scala有一个非常通用,丰富,强大,可组合的集合库;集合是高阶的(high level)并暴露了一大套操作方法。很多集合的处理和转换可以被表达的简洁又可读,但不审慎地用它们的功能也会导致相反的结果。每个Scala程序员应该阅读 集合设计文档;通过它可以很好地洞察集合库,并了解设计动机。
总使用最简单的集合来满足你的需求
层级
集合库很大:除了精心设计的层级(Hierarchy)——根是 Traversable[T] —— 大多数集合都有不可变(immutable)和可变(mutable)两种变体。无论其复杂性,下面的图表包含了可变和不可变集合层级的重要差异。
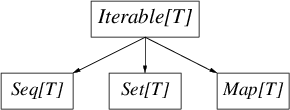
Iterable[T] 是所有可遍历的集合,它提供了迭代的方法(foreach)。Seq[T] 是有序集合,Set[T]是数学上的集合(无序且不重复),Map[T]是关联数组,也是无序的。
集合的使用
优先使用不可变集合。不可变集合适用于大多数情况,让程序易于理解和推断,因为它们是引用透明的( referentially transparent )因此缺省也是线程安全的。
使用可变集合时,明确地引用可变集合的命名空间。不要用使用import scala.collection.mutable._ 然后引用 Set ,应该用下面的方式替代:
import scala.collections.mutable
val set = mutable.Set()这样就很明确在使用一个可变集合。
使用集合类型缺省的构造函数。每当你需要一个有序的序列(不需要链表语义),用 Seq() 等诸如此类的方法构造:
val seq = Seq(1, 2, 3)
val set = Set(1, 2, 3)
val map = Map(1 -> "one", 2 -> "two", 3 -> "three")这种风格从语意上分离了集合与它的实现,让集合库使用更适当的类型:你需要Map,而不是必须一个红黑树(Red-Black Tree,注:红黑树TreeMap是Map的实现者)
此外,默认的构造函数通常使用专有的表达式,例如:Map() 将使用有3个成员的对象(专用的Map3类)来映射3个keys。
上面的推论是:在你自己的方法和构造函数里,适当地接受最宽泛的集合类型。通常可以归结为Iterable, Seq, Set, 或 Map中的一个。如果你的方法需要一个 sequence,使用 Seq[T],而不是List[T]
风格
函数式编程鼓励使用流水线转换将一个不可变的集合塑造为想要的结果。这常常会有非常简明的方案,但也容易迷糊读者——很难领悟作者的意图,或跟踪所有隐含的中间结果。例如,我们想要从一组语言中汇集不同的程序语言的投票,按照得票的顺序显示(语言,票数):
val votes = Seq(("scala", 1), ("java", 4), ("scala", 10), ("scala", 1), ("python", 10))
val orderedVotes = votes
.groupBy(_._1)
.map { case (which, counts) =>
(which, counts.foldLeft(0)(_ + _._2))
}.toSeq
.sortBy(_._2)
.reverse上面的代码简洁并且正确,但几乎每个读者都不能理解作者的原本意图。一个策略是声明中间结果和参数:
val votesByLang = votes groupBy { case (lang, _) => lang }
val sumByLang = votesByLang map { case (lang, counts) =>
val countsOnly = counts map { case (_, count) => count }
(lang, countsOnly.sum)
}
val orderedVotes = sumByLang.toSeq
.sortBy { case (_, count) => count }
.reverse代码也同样简洁,但更清晰的表达了转换的发生(通过命名中间值),和正在操作的数据的结构(通过命名参数)。如果你担心这种风格污染了命名空间,用大括号{}来将表达式分组:
val orderedVotes = {
val votesByLang = ...
...
}性能
高阶集合库(通常也伴随高阶构造)使推理性能更加困难:你越偏离直接指示计算机——即命令式风格——就越难准确预测一段代码的性能影响。然而推理正确性通常很容易;可读性也是加强的。在Java运行时使用Scala使得情况更加复杂,Scala对你隐藏了装箱(boxing)/拆箱(unboxing)操作,可能引发严重的性能或内存空间问题。
在关注于低层次的细节之前,确保你使用的集合适合你。 确保你的数据结构没有不期望的渐进复杂度。各种Scala集合的复杂性描述在这儿。
性能优化的第一条原则是理解你的应用为什么这么慢。不要使用空数据操作。在执行前分析[1]你的应用。关注的第一点是热循环(hot loops) 和大型的数据结构。过度关注优化通常是浪费精力。记住Knuth(高德纳)的格言:“过早优化是万恶之源”。
如果是需要更高性能或者空间效率的场景,通常更适合使用低级的集合。对大序列使用数组替代列表(List) (不可变Vector提供了一个指称透明的转换到数组的接口) ,并考虑使用buffers替代直接序列的构造来提高性能。
Java集合
使用 scala.collection.JavaConverters 与Java集合交互。它有一系列的隐式转换,添加了asJava和asScala的转换方法。使用它们这些方法确保转换是显式的,有助于阅读:
import scala.collection.JavaConverters._
val list: java.util.List[Int] = Seq(1,2,3,4).asJava
val buffer: scala.collection.mutable.Buffer[Int] = list.asScala

更多建议: