
 免费 AI IDE
免费 AI IDE

分布式缓存介绍
原文出处:http://weibo.com/p/1001643872772421209951
作者:赖佳俊@LierD

微博作为目前最大的中文社交媒体平台,拥有着上亿的日活用户。我们每天都会面临各种非常具有挑战性的业界技术难题。其中最具挑战性的几类问题是:
-
海量数据存储。微博总量已经超过千亿数据。海量数据的存取是一个非常大的技术挑战
-
巨大的并发请求。主feed接口的设计需要面对4倍于日常请求峰值的情况。
- SLA要求高。核心系统需要保证至少4个9的稳定性,核心接口平均响应时间1s内需要达到4个9
我们在解决上述的几类挑战中,结合自身的业务场景以及实际请求情况,设计出了高容量、可扩展、具有稳定性保障等特点的服务架构。本文主要结合微博平台的业务场景以及个人对分布式缓存的使用经验和体会来做说明介绍。
文章主要从以下几个方面来展开:
(1)缓存介绍,包括缓存的引入,缓存内存分配策略,以及淘汰算法等基本要点说明
(2)分布式缓存架构,主要结合平台缓存使用中碰到的问题以及一些考虑点,说明缓存系统的变迁。
1. 缓存介绍
1.1 为什么引入缓存
在传统的后端架构中,由于请求量以及响应时间要求不高,我们经常采用单一的db的结构。如下图1 所示,应用服务器直接存取DB。这种架构简单,但也存在着如图中所描述的问题,即DB存在性能瓶颈,随着请求量的增加,单DB无法继续稳定提供服务。
对于请求量不大的场景,我们可以通过对DB进行读写分离、一主多从、硬件升级(SSD)等方式提升系统的承载能力以及冗余能力,但这几种提升方式存在着以下几个缺陷:
(1)性能提升有限。很难得到量级上的提升,而大部分互联网产品直接面对着千万级用户访问,单一使用db的结构,难以达到性能要求
(2)成本高昂,为了达到N倍的承载能力的提升,需要至少N倍以上DB服务器
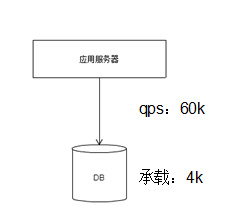
图1 传统服务架构
那么我们是否有更好的方式来做呢?
相信大家在学习操作系统的时候,一定看过如图2 类似的一组数据:

图2 各类存储介质的访问速度
从图2中可以看到,一次内存寻址的时间大概在100ns,顺序从内存中获取1MB数据的时间大概在250000ns。对应的,我们可以看到一次磁盘寻址以及顺序读取磁盘的速度大概在千万ns级别。这里我们可以得出一个结论,也即内存数据的获取速度大概在磁盘的获取速度的两个数量级。也因此我们可以通过引入缓存中间件,来提高系统整体的承载能力,原有的单层db结构也可以变为如图3所示的缓存+db结构。
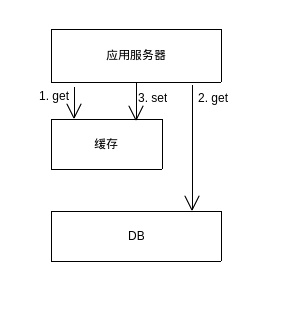
图3 DB+缓存
通过在应用服务与DB中间引入缓存层,我们可以得到如下三个好处:
(1)读取速度得到提升
(2)系统扩展能力得到大幅增强。我们可以通过加缓存,来让系统的承载能力提升
(3)总成本下降,单台缓存即可承担原来的多台DB的请求量,大大节省了机器成本
常见的缓存服务有本地缓存,memcached,redis等。他们各有自己的特点,本文以下内容主要是结合微博对于memcached一些使用来做讲解
1.2 Memcached
1.2.1 Memcached介绍
Memcached 是一个高性能的分布式内存对象缓存系统,广泛应用于动态Web应用,以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站的访问速度。
Memcached都有哪些特点呢?
-
本身是一个kv存储系统。存储的时候,需要指定key以及对应的value;获取的时候,只能通过key获取
-
协议简单,只支持简单的命令如:set、get、cas、delete、stats、incr、decr等,而无类似于mysql的select、join等复杂的sql命令。所有的命令以及数据都是以文本的形式传递,这也就意味着mc的协议无需特殊的客户端解析工具。我们可以通过在终端telnet进行命令传递以及数据获取。
-
支持设定过期时间
- 支持LRU等淘汰算法
1.2.2 Memcached的安装以及使用
Memcached的安装可以通过在官网上下载源码的方式安装:http://memcached.org/
相关安装教程可以参考官网安装步骤,亲测有效~:http://code.google.com/p/memcached/wiki/NewInstallFromSource
安装完成后,可以在linux终端执行以下命令启动 ./memcached -l 11211
新启一个终端,敲入命令telnet localhost 11211,即进入命令行模式
下面我们一起来试试Memcached hello world调用:
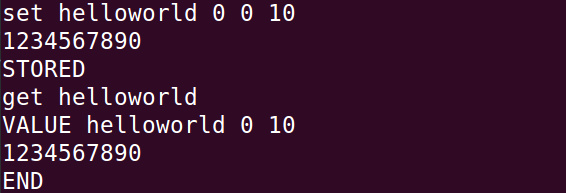
图4 memcached helloworld
因本文篇幅有限,具体命令不再展开描述,大家如果感兴趣可以通过官网的链接:http://code.google.com/p/memcached/wiki/NewCommands 了解。
1.2.3 Memcached内存分配原理介绍
掌握Memcached的安装、使用命令,其实对大部分的同学来说已经足以开展相关开发工作了。但当碰到一些线上问题的时候,单纯的会用Memcached是无法快速、合理的分析问题所在的。所以接下来我们将介绍Memcached的内存分配管理原理。
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块, 以完全解决内存碎片问题。
在介绍memcached的内存分配原理之前,需要跟大家说明以下几个关键的名词的概念:
item
一个待存储的元素,按字节计算大小,可以理解为一个物品
Chunk
用于缓存item的内存空间。可以理解为一个储物格
Slab Class
特定大小的chunk的组。可以理解为储物格按大小进行分类,如80B作为一类,96B作为一类....
Page
分配给Slab class的内存空间,默认是1MB。分配给Slab之后根据slab class的大小切分成chunk。可以理解为一个page是一个固定大小的柜子,上面可以按slab class进行分割,一个柜子只能按一个slab class进行分割。柜子上的格子数为柜子大小/ 储物格的大小
介绍完上述的几个基本概念后,我们可以来看看mc在分配内存的时候是怎么处理的。
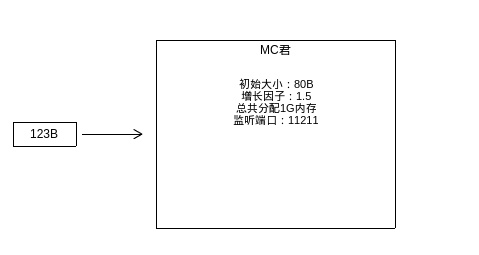
图5 memcached 初始化示意图
如图5为一个memcached示例在启动的时候,可以指定的一些参数,初始大小为slab class的起始大小,增长因子为下一个slab class是初始因子的倍数。如图中所示,初始大小为80B,增长因子为1.5。则mc在启动后,会按下图生成slab class表。
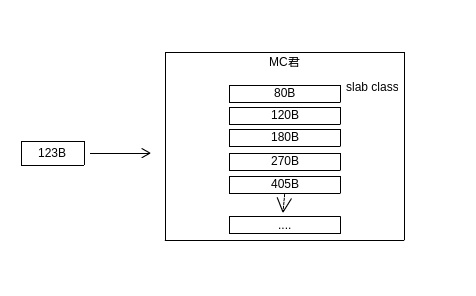
图6 slab分布图
完成初始后,当某一个请求到来的时候——如图中所示由一个123B大小的元素希望找到存储空间,memcached会通过slab class表找到最合适的slab class:比元素大的最少的那个,在图中场景下为180B,即使所需的空间只要123B。
此时Memcached示例并没有分配任何的空间给180B的slab进行管理。所以为了能让请求的元素能存储上,Memcached实例会分配1 个page给180这个slab(在默认情况下为1MB实际内存)。
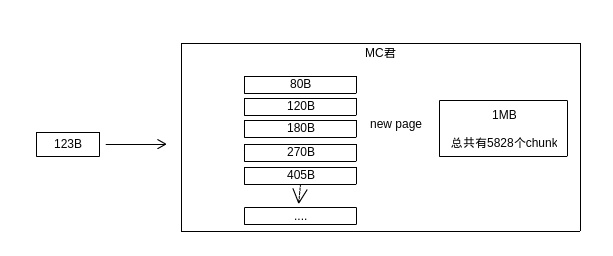
图 7 page分配图
180B slab class在获取到1MB的空间后,会按照自己的大小对page进行分隔,也即1MB/180=5828个具体的存储空间(chunk)。此时,123B的请求就可以被存储起来了。
随着时间的慢慢推移,memcached的内存空间会逐步被分配完,如下图8所示:
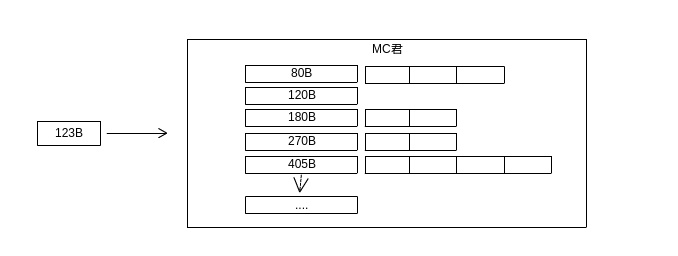
图 8 内存slab分配图
我们可以看到,memcached划分给每个slab的page数是不均等的,存在部分的slab是可能一个page都分配不到的。
假设所有的内存都分配完,同时每个slab内部的chunk也都分配完了。此时又来了一个新的元素123B,那么就会触发memcached的淘汰机制了。
memcached首先会查看180B的slab是否存在过期的元素,如果存在,则先清理部分,预留空位。如果180B这个slab的数据都比较热(没有过期),则按LRU进行淘汰。需要注意的是,淘汰是在slab内部进行的,也即在上面的场景中只有180Bslab内部进行淘汰剔除,对于其他的slab,是没有受到影响的。memcached也不会回收比较空余的其他slab的page。也即一个page被分配给某个slab后,他将一直被这个slab所占用,永远无法被mc回收,直到memcached重启。
这个特性被称为Memcached的钙化问题:Memcached在线上跑了一段时间后,内存按原始访问模式分配内存。当访问模式变更后,原有的分配模式可能导致缓存频繁出现数据剔除问题。最典型的场景即为内存尚有空余,但一直有数据被剔除,命中率一直上不去。对于这种情况,解决方法为重启缓存。
1.2.4 小结
上面两节中我们主体介绍了Memcached的使用以及内部的一些内存分布原理。相信大家在自己动手操作过后,会有一个较深的影响。在实际的使用中,除了关注缓存本身的一个使用外,我们还会有其他一些关注点。如高可用、扩展性等,这些关注点的实现并不是单纯依靠单一服务节点即可。为了能够满足上述的几个关注点,我们需要引入分布式缓存结构。
2. 分布式缓存
2.1 分布式?
考虑之前在缓存引入小节中所描述的,我们在原有的单层db结构中引入了缓存memcached:
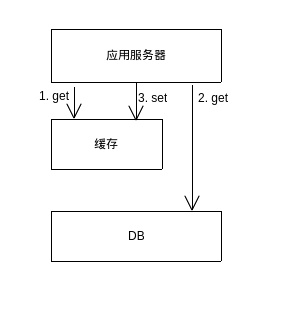
图 9 DB+缓存
在这种单实例缓存架构下,随着业务规模的不断增长,我们发现存在如下几个问题:
(1)容量问题
单一服务节点无法突破单机内存上限。目前微博数据已经超过千亿数据,虽然无需所有数据都放入缓存当中,但在保证一定的命中率的情况下(注:微博核心缓存命中率需要达到99%)缓存部分数据,也需要以百GB甚至是TB为单位的内存容量。而单台服务器的内存总有上限(目前微博使用的常用服务器内存上限128G),也即单实例缓存无法满足缓存所有数据的需要
(2)服务高可用(HA)
在单实例场景下,缓存如果因为网络波动、机器故障等原因不可用,原来由缓存承担的请求会全部落到DB上,最终系统会如同雪崩般,全部crash。
(3)扩展问题
单一服务节点无法突破单实例请求峰值上限。微博业务是存在热点突发事件的,也即随时会有可能出现数倍于日常请求峰值的情况。虽然我们在做资源的评估的时候,会确保资源的冗余度足够满足请求翻倍(一般为2~4倍)的情况。但我们也需要后端资源是可以线性扩展的
下面我们也会针对上面的几个问题,一步一步说明相应的解决方案。
2.2 分布式缓存实现
微博线上服务都是由多个服务端节点存储数据。由于memcached本身不支持分布式,所以需要客户端或者中间层代理实现分布式节点获取。在今天的描述中,为了简化问题,会主要以客户端实现分布式为主,即应用服务器(客户端)根据内部的算法,选择特定的缓存节点,存取数据。
2.2.1 数据分片(Sharding)
前面提到单实例memcached主要会有以下几个问题:
(1)请求量请求量超过单端口可承受极限
(2)数据容量超过单实例内存容量。
为了解决以上两个问题,我们的做法是从单端口实例扩展为一组实例。一组memcached由多个memcached实例组成,每个实例上只缓存数据总量的一部分数据,客户端在请求的时候,需要决定从哪个memcached中获取数据(hash)。
常见的hash算法可以使用:
(1)取模hash

图 10 取模hash
如图10所示,客户端根据请求的key,做取模,最终根据结果选择对应的memcached节点。这种方式实现简单。易于理解,缺点在于加减节点的时候,会造成较大的震荡:每加、减一个节点,hash方式全部改变,整体命中率会下降的非常快。
(1)一致性hash
一致性哈希的算法描述可以参考
https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
一致性哈希算法的主要优点在于加减节点,对于服务整体的震荡较小。并且在某个节点crash后,可以将后续请求,转移至另一个节点中,具备一定的防单点特性。
2.2.2 主从双层结构
从单台实例增加到一组缓存后,我们可以解决单端口容量、访问量不足的问题,但是如果出现某一台缓存挂了的情况。请求依然会落到后端的DB上。
上面也提到了一致性hash的算法,可以通过一致性hash的方式,来减少损失。
但基于一致性哈希策略的分布式实现在微博业务场景下也存在一些问题:
(1)微博线上业务对缓存命中率要求高。某台缓存挂了,会导致缓存整体命中率下降(即使一致性hash会在一定时间后将数据重新种到另一个节点上),对于命中率要求在99%以上的Feed流核心业务场景来说,命中率的下降是难以接受的
(2)一致性hash存在请求漂移的情况,假设某一段时间服务因网络因素访问某个服务节点失败,则在这时候,会将数据的更新、获取都迁移到下一个节点上。后续网络恢复后,应用服务探测到服务节点可用,则继续从原服务节点中获取数据,这就导致了在故障期间所做的更新操作,对于原服务节点不可见了
目前我们对于这种单点问题主要是通过引入主从缓存结构来解决的。主从结构示意图如下图11所示:
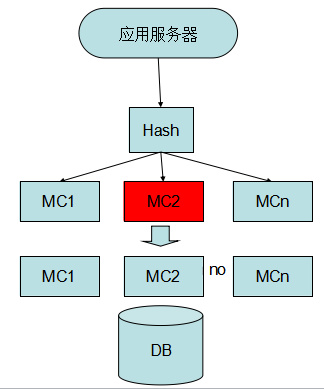
图 11 主从双层结构缓存
服务端在上行逻辑中,进行双写操作——由应用服务负责更新master、slave数据。
下行获取数据,先获取master数据,当master返回空,或者无法取到数据的时候,访问slave。
在这种模式下,为了避免两份数据带来的不一致问题,需要以master数据为准。即如果有更新数据操作,需要从master中获取数据,再对master进行cas更新。更新成功后,才更新slave。如果cas多次后都失败,则对master、slave进行delete操作,后续让请求穿透回种即可。
2.2.3 横向线性扩展
在双层结构下,我们可以很好的解决单点问题,即某一个节点如果crash了,请求可以被slave承接住,请求不会直接落在DB上。
但这种架构仍然存在一些问题:
(1)带宽问题。由于存在热点访问的情况,线上经常出现单个服务节点的带宽跑满的情况。
(2)请求量问题。随着业务的不断发展,并发请求数超过了单个节点的机器上限。数据分片、双层结构都不能解决这种问题。
上面的两个问题,其实总结起来是如何快速横向扩展系统的支撑能力。对于这个问题,我们的解决思路为增加数据的副本数。即让数据副本存在于多个节点中,从而平摊原本落在一个节点的请求。
从我们经验来看,对于线性扩展,可以在原来的master上引入一层L1层缓存。整体示意图如12所示:
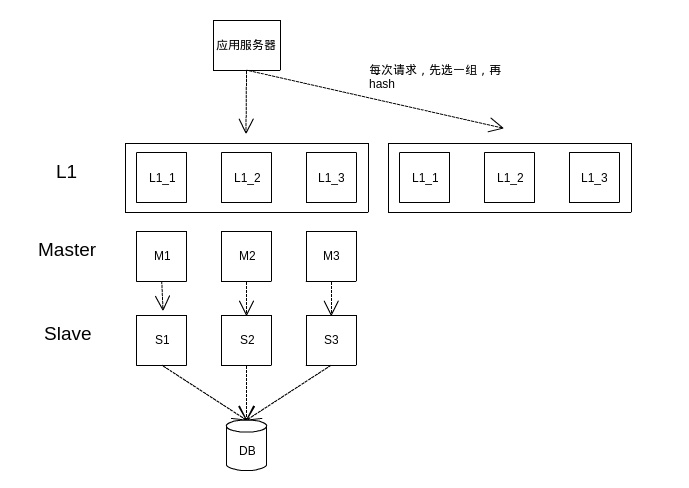
图12 采用L1的缓存架构
上行操作需要对L1进行多写。写缓存的顺序为master-slave-L1(所有),写失败则进行delete操作,后续由穿透请求进行回种。
L1可以由多组缓存组成,每组缓存相互独立。应用服务在获取数据的时候,先从L1中选取一组资源,然后再进行hash选取特定节点。对于multiget的场景也是先选取一组缓存,然后才对这组缓存进行multiget操作。如果L1获取不到数据,再依次获取master、slave数据。获取成功,则回种到L1中。
在采用L1的模式中,数据也是以master中数据为主的。即如果有更新数据的需要,需要从master中获取数据原本,再进行cas更新。如果cas更新成功,才同时更新slave、L1资源。如果对master的操作失败,则进行delete all操作,让后续请求穿透回种。
当线上流量、请求量达到一个水位的时候,我们会进行L1的扩容——增加一组、或几组L1缓存,从而提升系统整体的承载能力。此时系统的整体响应请求量是可以做到线性扩展的。
可以看到,双层结构下,slave作为主的备份存在。假设线上master缓存命中率为99%,则落在slave上的请求只有1%,并且这1%的请求都是很偏、很少人访问到的。可以想象,在这种情况下,如果master真的出现问题,请求全部落在slave上,slave也是没有任何数据可供访问的。Slave作为防单点措施是失败的。
引入L1后,slave过冷并没有被解决,同时,由于master被放置到L1之下,也遇到了slave的问题,master的数据也存在过冷的风险。为了解决上面的问题,我们在线上配置的时候,会将整组slave做为L1的一组资源进行配置,让slave以L1的身份承担部分的热请求。同时为了解决master过冷的问题,我们也会让应用服务在选择L1的时候有一定的概率落空,从而让master作为L1逻辑分组,去承担部分热请求。整体结构图如图13所示:
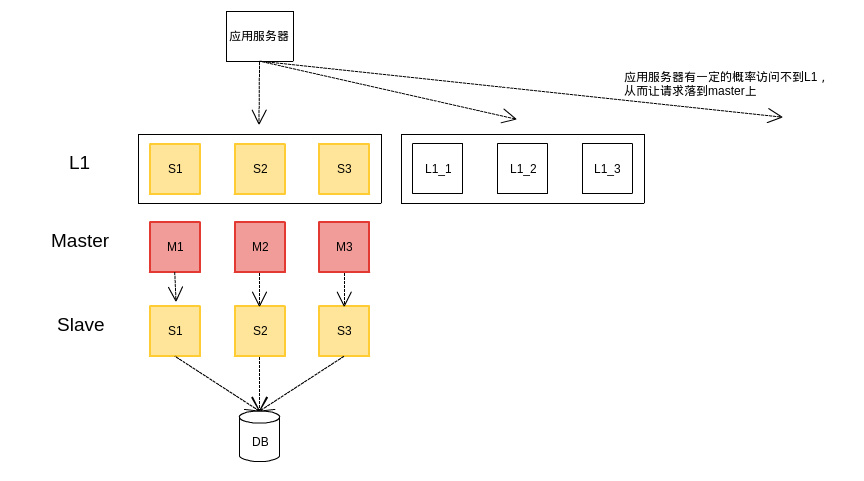
图13 slave、master同时作为L1架构
结尾:
本文主要结合目前微博平台的线上业务场景,根据个人对memcached的使用的经验,以及分布式架构情况做了介绍。行文仓促,肯定有很多细节需要继续完善,如果有问题或者建议,可以微博私信 @微博平台架构 或讲师 @LierD 一起继续探讨。
随着微博业务的蓬勃发展,相信还会有更多的技术挑战在等着我们去解决,去征服。我们也希望看到本文的小伙伴以及有志于做一些不一样的互联网产品的小伙伴们,能够加入我们,跟我们一起去攀登技术高峰~
新兵训练营简介
微博平台新兵训练营活动是微博平台内部组织的针对新入职同学的团队融入培训课程,目标是团队融入,包括人的融入,氛围融入,技术融入。当前已经进行4期活动,很多学员迅速成长为平台技术骨干。
具体课程包括《环境与工具》《分布式缓存介绍》《海量数据存储基础》《平台RPC框架介绍》《平台Web框架》《编写优雅代码》《一次服务上线》《Feed架构介绍》《unread架构介绍》
微博平台是非常注重团队成员融入与成长的团队,在这里有人帮你融入,有人和你一起成长,也欢迎小伙伴们加入微博平台,欢迎私信咨询。
讲师简介
赖佳俊(微博昵称:@LierD ),2013年7月毕业于哈尔滨工业大学后,加入新浪微博工作至今,担任系统研发工程师。曾先后参与微博Feed流优化、后端服务稳定性建设等项目。关注jvm调优,微服务,分布式存储系统。微博平台新兵训练营二期学员.
业余爱好三国杀,dota,喜欢自己做饭下厨希望能在微博的平台上认识到更多优秀的小伙伴,一起交流,一起成长


更多建议: