
 免费 AI IDE
免费 AI IDE

SAS连接数据集
可以使用SET语句连接多个SAS数据集以提供单个数据集。 在连接的数据集中的观察的总数是原始数据集中的观察的数量的总和。 观察的顺序是连续的。 来自第一数据集的所有观察结果后面是来自第二数据集的所有观察结果,并依此类推。
所有组合数据集具有相同的变量,但是如果它们具有不同数量的变量,则在结果中出现所有变量,对于较小数据集具有缺失值。
句法
SAS中SET语句的基本语法是:
SET data-set 1 data-set 2 data-set 3.....;
以下是所使用的参数的说明:
- data-set1,data-set2是一个接一个写入的数据集名称。
例
考虑在两个不同数据集中可用的组织的员工数据,一个用于IT部门,另一个用于非IT部门。 要获得所有员工的完整详细信息,我们使用如下所示的SET语句连接两个数据集。
DATA ITDEPT; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA=All_Dept; RUN;
当执行上面的代码,我们可以得到下面的输出。
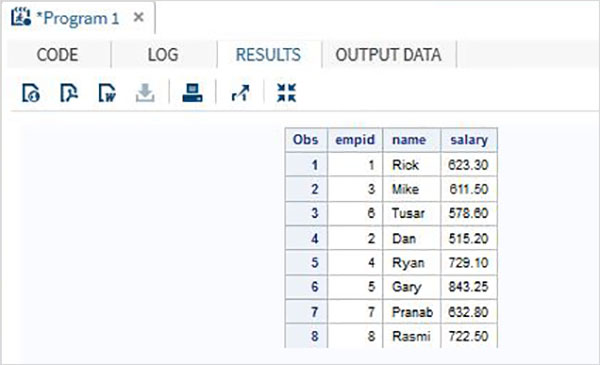
方案
当我们在用于级联的数据集中有许多变化时,变量的结果可以不同,但是级联数据集中的观测值的总数总是每个数据集中的观测值的总和。 我们将在下面考虑这种变化的许多情况。
不同数量的变量
如果原始数据集中的一个具有更多数量的变量而另一个数据集,则数据集仍然被组合,但是在较小的数据集中,这些变量显示为缺失。
例
在下面的例子中,第一个数据集有一个名为DOJ的额外变量。 在结果中,第二个数据集的DOJ值将显示为缺失。
DATA ITDEPT; INPUT empid name $ salary DOJ date9. ; DATALINES; 1 Rick 623.3 02APR2001 3 Mike 611.5 21OCT2000 6 Tusar 578.6 01MAR2009 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA=All_Dept; RUN;
当执行上面的代码,我们可以得到下面的输出。

不同的变量名
在这种情况下,数据集具有相同数量的变量,但变量名在它们之间不同。 在这种情况下,正态连接将产生结果集中的所有变量,并给出不同的两个变量的缺失结果。 虽然我们不能更改原始数据集中的变量名称,但我们可以在我们创建的连接数据集中应用RENAME函数。 这将产生与正常连接相同的结果,但是当然使用一个新的变量名称代替原始数据集中存在的两个不同的变量名称。
例
在下面的示例中,数据集ITDEPT具有变量名ename,而数据集NON_ITDEPT具有变量名empame。 但这两个变量代表相同的类型(字符)。 我们在SET语句中应用RENAME函数,如下所示。
DATA ITDEPT; INPUT empid ename $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid empname $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT(RENAME =(ename=Employee) ) NON_ITDEPT(RENAME =(empname=Employee) ); RUN; PROC PRINT DATA=All_Dept; RUN;
当执行上面的代码,我们可以得到下面的输出。
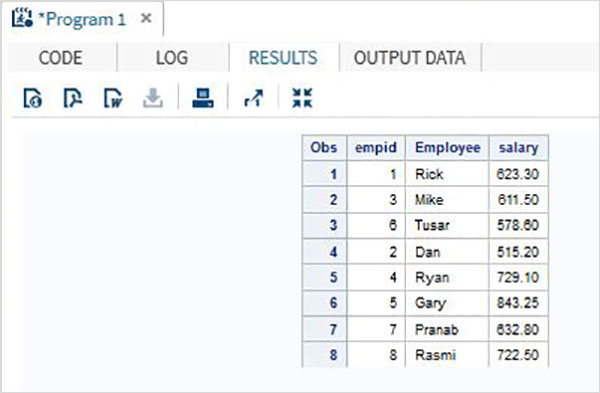
不同的变量长度
如果两个数据集中的变量长度不同,则连接的数据集将具有其中一些数据对于具有较小长度的变量被截断的值。 如果第一个数据集的长度较小,就会发生这种情况。 为了解决这个问题,我们对数据集应用更高的长度,如下所示。
例
在下面的示例中,变量ename在第一个数据集中的长度为5,在第二个数据集中为7。 当连接时,我们应用连接数据集中的LENGTH语句将枚举长度设置为7。
DATA ITDEPT; INPUT empid 1-2 ename $ 3-7 salary 8-14 ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ; SET ITDEPT NON_ITDEPT ; RUN; PROC PRINT DATA=All_Dept; RUN;
当执行上面的代码,我们可以得到下面的输出。
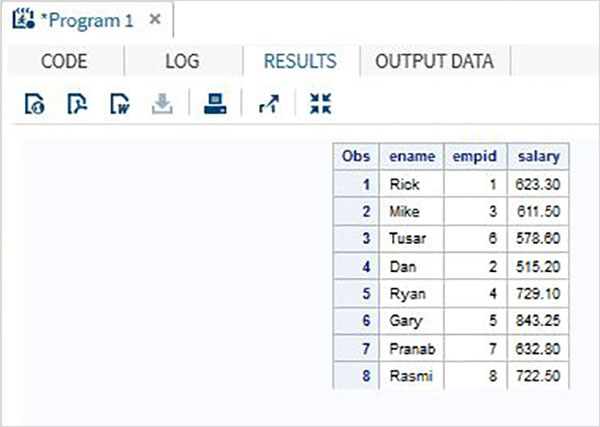


更多建议: