
 免费 AI IDE
免费 AI IDE

Samza 功能预览
本节内容
- 概观
- 试试看
- 建筑
- 高级API
- 灵活部署模式
概观
Samza 0.13.0 引入了新的编程模型和新的部署模型,它们作为预览被发布,因为它们代表了开发人员如何与Samza合作的重大改进,因此对早期采用者和Samza开发社区来说,有助于实验该版本并提供反馈。以下内容介绍新功能和链接到教程,演示如何使用它们。请尝试并发送反馈给开发者邮件列表。
试试看
想跳过所有细节并获得一些实际经验吗?有三个教程可以帮助您了解在 YARN 和嵌入式模式下运行 Samza 应用程序以及使用高级 API 进行编程:
- YARN部署 - 在 YARN 上运行预先存在的维基百科应用程序并观察输出。
- 高级API代码演练 - 逐步构建维基百科应用程序。
- ZooKeeper部署 - 使用 ZooKeeper 协调运行预先存在的维基百科应用程序并观察输出。
建筑
介绍
Samza 高级 API 提供统一的方式来处理流和批量数据。您可以在单个程序中使用地图,过滤器,窗口和连接等操作员来描述端到端应用程序逻辑,以完成以前所需的多个作业。API 旨在便携式。相同的应用程序代码可以批处理或流式传输模式,嵌入式或集群管理器环境部署,并可以通过简单的配置更改在Kafka,Kinesis,HDFS或其他系统之间切换。这种可移植性是由以下部分所述的新架构启用的。
概念
Samza 的架构已经被大修,具有不同的层次,可以处理应用程序开发的每一个阶段。下图显示了 Apache Samza 架构与高级 API 的概述。
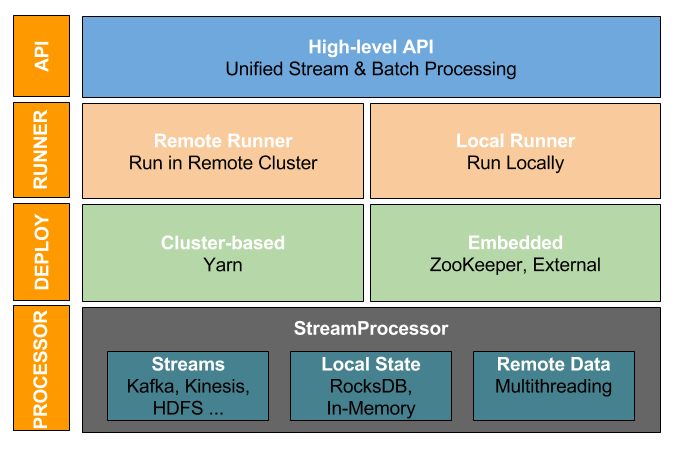
建筑中有四层,以下部分描述每个图层。
I.高级API
高级 API 提供库来定义应用程序逻辑。该StreamApplication是您的应用程序必须贯彻执行中央的抽象。您首先将输入声明为MessageStream的实例。然后,您可以在每个 MessageStream 上应用运算符,如地图,过滤器,窗口和连接,以在单个程序中定义整个端到端数据处理。
要深入了解高级 API,请参阅下面的高级API部分。
II.ApplicationRunner
Samza 使用ApplicationRunner来运行流应用程序。ApplicationRunner 生成配置(如输入/输出流),创建中间流,并开始执行。ApplicationRunner 有两种类型:
第一种:RemoteApplicationRunner - 将应用程序提交到远程集群。该运行程序通过 run-app.sh 脚本调用。
要使用 RemoteApplicationRunner,请设置以下配置:
# The StreamApplication class to run
app.class=com.company.job.YourStreamApplication
job.factory.class=org.apache.samza.job.yarn.YarnJobFactory然后使用 run-app.sh 在远程集群中运行应用程序。该脚本将调用 RemoteApplicationRunner,它将使用 job.factory.class 指定的工厂启动一个或多个作业。
第二种:LocalApplicationRunner - 在JVM进程中运行该应用程序。例如,要使用 ZooKeeper 在多台机器上启动应用程序进行协调,可以在各种机器上运行多个 LocalApplicationRunner实例。应用程序加载后,他们将通过 ZooKeeper 启动它们的操作。以下是使用 LocalApplicationRunner 在程序中运行 StreamApplication 的示例:
public static void main(String[] args) throws Exception {
CommandLine cmdLine = new CommandLine();
Config config = cmdLine.loadConfig(cmdLine.parser().parse(args));
LocalApplicationRunner localRunner = new LocalApplicationRunner(config);
StreamApplication app = new YourStreamApplication();
localRunner.run(app);
// Wait for the application to finish
localRunner.waitForFinish();
System.out.println("Application completed with status " + localRunner.status(app));
}按照ZooKeeper部署教程进行尝试。
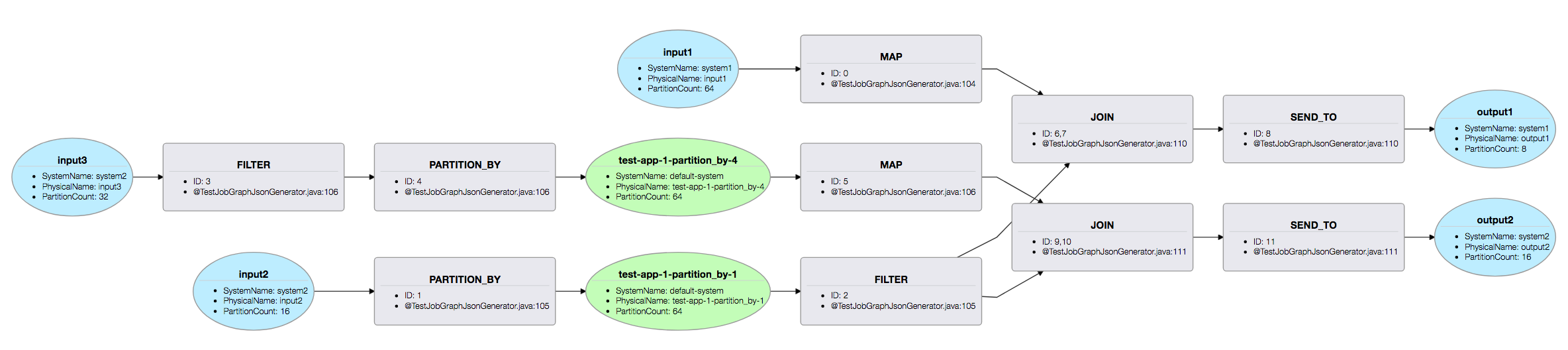
执行计划
ApplicationRunner 在开始执行处理逻辑之前生成一个物理执行计划。该计划表示应用程序的运行时结构。特别地,它提供对生成的中间流的可见性。一旦部署了工作,该计划可以被看作如下:
- 对于使用 run-app.sh 启动的应用程序,Samza 将在您的应用程序部署目录下创建一个计划目录,并在其中编写 plan.json 文件。
- 对于使用自己的脚本(例如 LocalApplicationRunner)启动的应用程序,请在与 bin 相同的级别创建一个计划目录,并指出 EXECUTION_PLAN_DIR 环境变量的位置。
要查看计划,请在浏览器中打开 bin / plan.html 文件。这是一个示例计划可视化:
III.执行模型
Samza 支持两种类型的执行模型:基于群集的执行和嵌入式执行。
在基于群集的执行中,Samza 将在多租户群集上运行和管理您的应用程序。萨姆支持 YARN。您可以实现自己的 StreamJob 和相应的 ResourceManagerFactory 来添加对另一个集群管理器的支持。
在嵌入式执行模型中,您可以在应用程序中使用 Sa mza 作为轻量级库。您可以旋转应用程序的多个实例,它们之间将分配和协调处理。此模式提供了在任意托管环境中运行应用程序的灵活性:它还支持可插拔协调逻辑,支持两种类型的协调开箱即用:
- 基于 ZooKeeper 的协调 - Samza 可以配置为使用 ZooKeeper 在应用程序的实例之间管理组成员资格和分区分配。这允许您通过关闭更多实例或缩小某些值来动态缩放应用程序。
- 外部协调 - Samza 可以在单个JVM本地运行您的应用程序,而无需协调,或者具有静态分区分配的多个JVM。当在诸如 Kubernetes 或 Amazon ECS 这样的集装箱化环境中运行时,这是非常有用的。
有关在嵌入式模式下运行 Samza 的更多详细信息,请参阅下面的灵活部署模型部分。
IV.处理器
Samza 应用程序的最低执行单元是处理器。它读取从ApplicationRunner生成的配置并处理 JobCoordinator 分配的输入流分区。它可以使用KeyValueStore实现(例如 RocksDB 或内存)和使用多线程的远程状态(例如 REST 服务)访问本地状态。
高级API
自从0.13.0版本以来,Samza 提供了一个新的高级 API,可以简化应用程序。此 API 支持重新分区,加窗和加入流等操作。您现在可以在几行代码中简洁地表达您的应用程序逻辑,并完成以前需要的多个作业。
代码示例
查看一些示例来查看高级 API 的操作。
- PageView AdClick Joiner演示了一系列AdViews加入了一系列 PageViews,例如分析哪些网页获得最多的广告点击。
- Pageview Repartitioner说明了重新分割引入的 PageViews 的流。
- PageView Sessionizer根据用户活动将进入的事件流分组到会话中。
- 按区域浏览量计算每个区域在翻滚时间间隔内的视图数量。
关键概念
StreamApplication
在使用 Samza 高级 API 编写流处理应用程序时,应实现StreamApplication并在 init 方法中定义处理逻辑。
public void init(StreamGraph graph, Config config) { … }例如,这里是一个 StreamApplication,它使用查看者的个人资料信息来验证和装饰页面浏览。
public class BadPageViewFilter implements StreamApplication {
@Override
public void init(StreamGraph graph, Config config) {
MessageStream<PageView> pageViews = graph.getInputStream(“page-views”..);
pageViews.filter(this::isValidPageView)
.map(this::addProfileInformation)
.sendTo(graph.getOutputStream(“decorated-page-views”..))
}
}MessageStream
顾名思义,MessageStream 表示消息流。StreamApplication 被描述为 MessageStreams 上的一系列转换。
您可以通过两种方式获取 MessageStream:
- 使用 StreamGraph.getInputStream 获取给定输入流的 MessageStream(例如,Kafka主题)。
- 通过使用地图,过滤器,窗口,连接等操作转换现有的 MessageStream。
典型Samza StreamApplication的解剖学
使用 Samza 高级 API 编写流处理应用程序有3个简单的步骤。
步骤1:获取输入流:
您可以使用 StreamGraph.getInputStream 获取输入流 ID(“page-views”)的 MessageStream。
MessageStream<PageView> pageViewInput = graph.getInputStream(“page-views”, (k,v) -> v);第一个参数 page-views 是逻辑流 ID。每个流 ID 与物理名称和系统相关联。默认情况下,Samza 使用流 ID 作为物理流名称,并访问使用属性 “job.default.system” 指定的默认系统上的流。但是,物理名称和系统属性可以在配置中被覆盖。例如,以下配置将流 ID“page-views” 定义为本地 Kafka 集群中 PageViewEvent 主题的别名。
streams.page-views.samza.system=kafka
systems.kafka.samza.factory=org.apache.samza.system.kafka.KafkaSystemFactory
systems.kafka.consumer.zookeeper.connect=localhost:2181
systems.kafka.producer.bootstrap.servers=localhost:9092
streams.page-views.samza.physical.name=PageViewEvent第二个参数 (k,v) -> v 是 MessageBuilder 函数,用于从传入的键和值构造消息。
步骤2:定义转换逻辑:
您现在可以将 StreamApplication 逻辑定义为 MessageStream 上的一系列转换。
MessageStream<DecoratedPageViews> decoratedPageViews
= pageViewInput.filter(this::isValidPageView)
.map(this::addProfileInformation);步骤3:将输出写入输出流:
最后,您可以使用 StreamGraph.getOutputStream 创建一个 OutputStream,并通过它发送已转换的消息。
// Send messages with userId as the key to “decorated-page-views”.
decoratedPageViews.sendTo(
graph.getOutputStream(“decorated-page-views”,
dpv -> dpv.getUserId(),
dpv -> dpv));第一个参数 decorated-page-views 是逻辑流 ID。该流 ID 的属性可以像输入流的流 ID 一样被覆盖。例如:
streams.decorated-page-views.samza.system=kafka
streams.decorated-page-views.samza.physical.name=DecoratedPageViewEvent第二和第三个参数定义提取器,将上游数据类型分别分成一个单独的键和值。
运营商
高级 API 支持常用的运算符,如地图,平面图,过滤器,合并,连接和窗口。大多数这些操作符接受相应的函数,这些函数是 Initable。
地图
将提供的1:1 MapFunction 应用于 MessageStream 中的每个元素,并返回已转换的 MessageStream。MapFunction 接收单个消息并返回单个消息(可能具有不同类型的消息)。
MessageStream<Integer> numbers = ...
MessageStream<Integer> tripled= numbers.map(m -> m * 3)
MessageStream<String> stringified = numbers.map(m -> String.valueOf(m))Flatmap
将提供的 1:n FlatMapFunction应用于 MessageStream 中的每个元素,并返回已转换的 MessageStream。FlatMapFunction 接收单个消息并返回零个或多个消息。
MessageStream<String> sentence = ...
// Parse the sentence into its individual words splitting by space
MessageStream<String> words = sentence.flatMap(sentence ->
Arrays.asList(sentence.split(“ ”))过滤
将提供的FilterFunction应用于 MessageStream 并返回已过滤的 MessageStream。FilterFunction 是一个谓词,用于指定是否应将消息保留在过滤的流中。FilterFunction 返回 false 的消息将被过滤掉。
MessageStream<String> words = ...
// Extract only the long words
MessageStream<String> longWords = words.filter(word -> word.size() > 15);
// Extract only the short words
MessageStream<String> shortWords = words.filter(word -> word.size() < 3);PartitionBy
使用提供的 keyExtractor 返回的键重新分区该 MessageStream,并返回已转换的 MessageStream。在重新分区期间通过中间流发送消息。
// Repartition pageView by userId
MessageStream<PageView> pageViews = ...
MessageStream<PageView> partitionedPageViews =
pageViews.partitionBy(pageView -> pageView.getUserId())合并
将 MessageStream 与所有提供的 MessageStream 合并,并返回合并的流。
MessageStream<ServiceCall> serviceCall1 = ...
MessageStream<ServiceCall> serviceCall2 = ...
// Merge individual “ServiceCall” streams and create a new merged MessageStream
MessageStream<ServiceCall> serviceCallMerged = serviceCall1.merge(serviceCall2)合并变换保留每个 MessageStream 的顺序,因此如果消息 m1 出现 m2 在任何提供的流之前,则 m1 也会出现 m2 在合并流之前。
作为 merge 实例方法的替代方法,您还可以使用MessageStream#mergeAll静态方法来合并 MessageStream 而不在初始流上操作。
发给
将此消息流中的所有消息发送到提供的 OutputStream。您可以指定要用于传出消息的密钥和值。
// Output a new message with userId as the key and region as the value to the “user-region” stream.
MessageStream<PageView> pageViews = ...
OutputStream<String, String, PageView> userRegions
= graph.getOutputStream(“user-region”,
pageView -> pageView.getUserId(),
pageView -> pageView.getRegion())
pageView.sendTo(userRegions);水槽
允许使用提供的SinkFunction从此 MessageStream 发送消息到输出系统。
这提供了比 sendTo 更多的控制,因为 SinkFunction 可以访问 MessageCollector 和 TaskCoordinator。例如,您可以选择手动提交偏移量,或使用 TaskCoordinator API 关闭作业。该运营商也可用于向非萨姆萨系统发送消息(如远程数据库,REST 服务等)
// Repartition pageView by userId.
MessageStream<PageView> pageViews = ...
pageViews.sink( (msg, collector, coordinator) -> {
// Construct a new outgoing message, and send it to a kafka topic named TransformedPageViewEvent.
collector.send(new OutgoingMessageEnvelope(new SystemStream(“kafka”,
“TransformedPageViewEvent”), msg));
} )加入
Join 运算符使用提供的成对JoinFunction从两个 MessageStream 中加入消息。当从第一流的消息提取的密钥匹配从第二个流中的消息提取的密钥时,消息被连接。每个流中的消息将保留提供的 ttl 持续时间,并且连接结果将在匹配发现时发出。
// Joins a stream of OrderRecord with a stream of ShipmentRecord by orderId with a TTL of 20 minutes.
// Results are produced to a new stream of FulfilledOrderRecord.
MessageStream<OrderRecord> orders = …
MessageStream<ShipmentRecord> shipments = …
MessageStream<FulfilledOrderRecord> shippedOrders = orders.join(shipments, new OrderShipmentJoiner(), Duration.ofMinutes(20) )
// Constructs a new FulfilledOrderRecord by extracting the order timestamp from the OrderRecord and the shipment timestamp from the ShipmentRecord.
class OrderShipmentJoiner implements JoinFunction<String, OrderRecord, ShipmentRecord, FulfilledOrderRecord> {
@Override
public FulfilledOrderRecord apply(OrderRecord message, ShipmentRecord otherMessage) {
return new FulfilledOrderRecord(message.orderId, message.orderTimestamp, otherMessage.shipTimestamp);
}
@Override
public String getFirstKey(OrderRecord message) {
return message.orderId;
}
@Override
public String getSecondKey(ShipmentRecord message) {
return message.orderId;
}
}窗口
窗口概念
Windows,触发器和 WindowPanes:窗口操作符将 MessageStream 中的传入消息分组为有限的窗口。每个发出的结果在窗口中包含一个或多个消息,称为 WindowPane。
窗口可以具有一个或多个关联的触发器,以确定何时发出窗口的结果。触发器可以是早期触发器,允许在窗口的所有数据到达之前推测出结果,或者延迟触发器允许处理窗口的延迟消息。
聚合器功能:默认情况下,发出的 WindowPane 将包含窗口的所有消息。您通常不会保留所有消息,而是为 WindowPane 定义一个更紧凑的数据结构,并在新消息到达时逐渐更新,例如在窗口中保留消息计数。为此,您可以提供一个聚合的FoldLeftFunction,它为每个添加到窗口的传入消息调用,并定义如何更新该消息的 WindowPane。
累积模式:窗口的累加模式确定从窗口发出的结果与同一窗口的先前发射结果相关。当窗口配置有早期或晚期触发器时,这特别有用。累积模式可以是丢弃或累积。
一个丢弃窗口清除在每一个发射窗口的所有状态。每次发射只会对应于从前一次发射窗口到达的新消息。
一个累加窗口保留从以前的排放窗口的结果。每个排放将包含从窗口开始到达的所有邮件。
窗口类型:
Samza 高级 API 目前支持翻滚和会话窗口。
翻滚窗口:一个翻滚窗口定义了一系列的流中连续的,固定大小的时间间隔。
例子:
// Group the pageView stream into 3 second tumbling windows keyed by the userId.
MessageStream<PageView> pageViews = ...
MessageStream<WindowPane<String, Collection<PageView>>> =
pageViews.window(
Windows.keyedTumblingWindow(pageView -> pageView.getUserId(),
Duration.ofSeconds(30)))
// Compute the maximum value over tumbling windows of 3 seconds.
MessageStream<Integer> integers = …
Supplier<Integer> initialValue = () -> Integer.MIN_VALUE
FoldLeftFunction<Integer, Integer> aggregateFunction = (msg, oldValue) -> Math.max(msg, oldValue)
MessageStream<WindowPane<Void, Integer>> windowedStream =
integers.window(Windows.tumblingWindow(Duration.ofSeconds(30), initialValue, aggregateFunction))会话窗口:会话窗口将 MessageStream 组合成会话。会话通过 MessageStream 捕获一段活动,并由间隙定义。关闭会话,如果没有新消息到达窗口以获得间隙时间,则会发出结果。
例子:
// Sessionize a stream of page views, and count the number of page-views in a session for every user.
MessageStream<PageView> pageViews = …
Supplier<Integer> initialValue = () -> 0
FoldLeftFunction<PageView, Integer> countAggregator = (pageView, oldCount) -> oldCount + 1;
Duration sessionGap = Duration.ofMinutes(3);
MessageStream<WindowPane<String, Integer> sessionCounts = pageViews.window(Windows.keyedSessionWindow(
pageView -> pageView.getUserId(), sessionGap, initialValue, countAggregator));
// Compute the maximum value over tumbling windows of 3 seconds.
MessageStream<Integer> integers = …
Supplier<Integer> initialValue = () -> Integer.MAX_INT
FoldLeftFunction<Integer, Integer> aggregateFunction = (msg, oldValue) -> Math.max(msg, oldValue)
MessageStream<WindowPane<Void, Integer>> windowedStream =
integers.window(Windows.tumblingWindow(Duration.ofSeconds(3), initialValue, aggregateFunction))已知的问题
目前,窗口和连接操作符缓冲内存中的消息。因此,消息可能在故障和重新启动时丢失。
灵活部署模式
介绍
在 Samza 0.13.0 之前,Samza仅支持使用 YARN进行 集群管理的部署。
使用 Samza 0.13.0,部署模式已被简化并与 YARN 分离。如果您喜欢集群管理,您仍然可以使用 YARN,或者您可以实现自己的扩展,以在其他集群管理系统上部署 Samza。但是如果你想避免集群管理系统呢?
Samza 现在可以将应用程序部署为具有可插拔协调的简单嵌入式库。使用嵌入式模式,您可以直接在应用程序中使用 Samza 处理器,并以任何您喜欢的方式进行部署。Samza 有一个可插拔的工作协调器层,用于执行领导选举,并为处理器分配工作。
本节将重点介绍新的嵌入式部署功能。
概念
我们来仔细看看嵌入式部署的工作原理。
上面的概念部分提供了能够灵活部署模型的层的概述。新的嵌入式模式进入了部署层。部署层包括向可用处理器分配输入分区。
有两种类型的分区分配模型可以通过配置中的 job.coordinator.factory 进行控制:
外部分区管理
通过外部分区管理,Samza 本身不管理分区。相反,它使用一个 PassthroughJobCoordinator 供奉由SystemStreamPartitionGrouper提供的任何分区映射。外部分区管理有两种常见的模式:
- 使用高级卡夫卡消费者 - 分区分配由高级卡夫卡消费者本身完成。要使用此模型,您需要实现和配置一个 SystemFactory,它提供了 yarn 高级消费者。然后,您需要将job.systemstreampartition.grouper.factory 配置为 org.apache.samza.container.grouper.stream.AllSspToSingleTaskGrouper,以使 yarn 的分区分配全都转到一个任务。
- 自定义分区 - 使用自定义分割器完成分区分配。石斑鱼的逻辑完全取决于你。此模型的一个实际示例是实现从配置读取静态分区分配的自定义分组器。
Samza 配备了 PassthroughJobCoordinatorFactory 一种便于这种类型的分区管理。
动态分区管理
使用动态分区,分区在运行时分布在可用处理器之间。如果可用处理器的数量发生变化(例如,如果有些处理器被关闭或添加),映射将被重新生成并重新分配给所有处理器。有关当前映射的信息包含在称为 JobModel 的特殊结构中。有一个领先的处理器生成 JobModel 并将其分发到其他处理器。领导人由“领导人选举”进程决定。
我们来仔细看看动态协调的工作原理。
协调服务
处理器的动态协调假定存在协调服务。该服务的主要职责是:
- 领导选举 - 选择一个单一的处理器,负责 JobModel 的计算和分发或创建中间流。
- 中央屏障和锁存器 - 处理器使用的协调原语。
- JobModel 通知 - 通知处理器有关新 JobModel 的可用性。
- JobModel 存储协调服务指示 JobModel 持久化的位置。
协调服务目前来自工作协调员工厂。Samza ZkJobCoordinatorFactory 有一个相应的实现 ZkCoordinationServiceFactory。
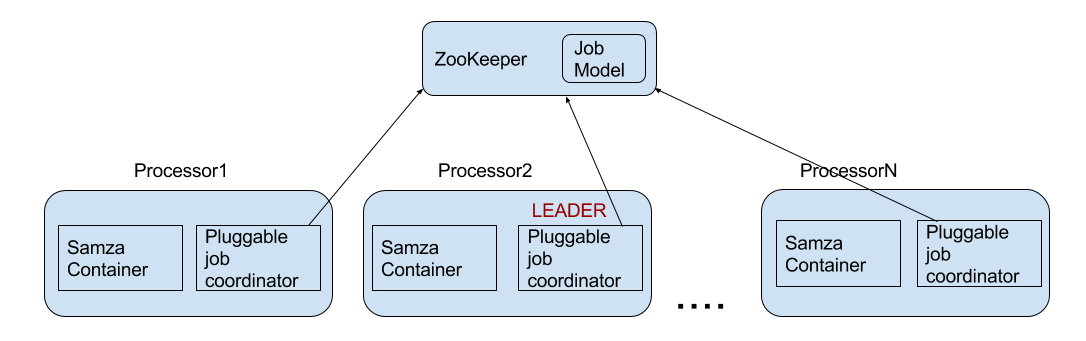
我们来看看基于 ZooKeeper 的嵌入式应用程序的协调顺序:
- 每个处理器(参与者)将向可插拔协调服务注册。在注册期间,它将提供自己的参与者 ID。
- 其中一名参赛者将当选为领导人。
- 领导者监督所有活跃参与者的名单。
- 每当参与者名单发生变化时,领导者将为当前参与者生成一个新的 JobModel。
- 新的 JobModel 将被推送到一个常见的存储。默认实现为此目的使用 ZooKeeper。
- 通知参与者新的 JobModel 可用。通过协调服务完成通知,例如 ZooKeeper。
- 参与者将停止处理,应用新的 JobModel,然后恢复处理。
下图显示了 ZooKeeper 协调服务实现中协调器的关系。
以下是协调服务的几个重要细节:
- 为了确保两个分区不被不同处理器处理两次,处理暂停,处理器在屏障上同步旦所有处理器都被暂停,就会应用新的 JobModel 并继续处理。使用协调服务实现屏障。
- 在启动和关机期间,处理器将陆续加入/离开。为了避免冗余的 JobModel 重新计算,有一个去抖动定时器等待一些短时间(默认为2秒,在将来的版本中可配置),以便更多的处理器加入或离开。每次处理器加入或离开时,定时器被复位。当定时器到期时,最终重新计算 JobModel。
- 如果处理器需要相邻或临时数据的本地存储,我们希望在重新启动时保持映射。为此,我们使用一些关于每个处理器的额外信息,它们唯一标识它及其位置。如果相同的处理器在相同的位置重新启动,我们将尝试为其分配相同的分区。这个地方信息应该能够在重新启动之后继续存在,所以它被存储在一个公共的存储器上(目前使用的是 ZooKeeper)。
用户指南
嵌入式部署旨在帮助希望更好地控制其应用程序部署的用户。因此,用户有责任配置和部署处理器。在 ZooKeeper 协调的情况下,您还需要配置 ZooKeeper 实例的 URL。
此外,每个处理器需要与协调服务一起使用的唯一 ID。如果位置关联性很重要,则该 ID 对于特定主机名上的每个处理器(假设本地存储服务)应该是唯一的。为了满足这一要求,Samza 使用ProcessorIdGenerator为每个处理器提供 ID。如果没有显式配置生成器,默认情况下将为每个处理器创建一个 UUID。
组态
要运行嵌入式 Samza 处理器,您需要使用 job.coordinator.factory 属性配置协调器服务。此外,目前有一个支持嵌入式模式的 taskname 分组,因此您必须明确配置。
我们来看看如何配置 Samza 附带的两个协调服务实现。
要使用基于 ZooKeeper 的协调,需要以下配置:
job.coordinator.factory=org.apache.samza.zk.ZkJobCoordinatorFactory
job.coordinator.zk.connect=yourzkconnection
task.name.grouper.factory=org.apache.samza.container.grouper.task.GroupByContainerIdsFactory要使用外部协调,需要以下配置:
job.coordinator.factory=org.apache.samza.standalone.PassthroughJobCoordinatorFactory
task.name.grouper.factory=org.apache.samza.container.grouper.task.GroupByContainerIdsFactoryAPI
如上面的概述部分所述,您可以使用 LocalApplicationRunner 从应用程序代码启动处理器,如下所示:
public class WikipediaZkLocalApplication {
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new LocalApplicationRunner(config);
WikipediaApplication app = new WikipediaApplication();
runner.run(app);
runner.waitForFinish();
}
}在上面的代码中,WikipediaApplication 是用高级API编写的应用程序。
请查看本教程,以便现在在机器上使用 ZooKeeper 协调运行此应用程序。
部署和缩放
您可以以任何您喜欢的方式部署应用程序实例。如果使用协调服务,您可以随时添加或删除实例,并且领导者的工作协调员(通过协调服务选举)将在去抖动时间后自动重新计算 JobModel,并将其应用于可用的处理器。所以,为了扩展你的应用程序,你只需要启动更多的处理器。
已知的问题
请注意0.13.0版本的嵌入式部署功能的以下问题。他们将在随后的版本中修复。
- 不支持 GroupByContainerCount 默认任务名称分组。
- 主机关联性未启用。
- 尚未提供 ZkJobCoordinator 指标。指标即将加入重新计算 JobModel 的数量读/写数领导人重选更多..
- LocalApplicationRunner 还不支持低级API。这意味着您不能使用 StreamTask 与 LocalApplicationRunner。
- 目前,对于使用此zk集群的所有应用程序,“app.id” 配置必须是唯一的。


更多建议: