
 免费 AI IDE
免费 AI IDE

卷2:第18章 Puppet part 1
18.1. 概述
Puppet 是一个用 Ruby 写的开源 IT 管理工具,用于数据中心自动化和服务器的管理,用户包括 Google, Twitter, 纽约证券交易所以及很多其他机构。Puppet 的主要维护者是 Puppet Labs,也就是 Puppet 项目的发起者。Puppet 可以管理从 2 台到 5 万台机器,管理员可以只有1个人或者是上百人。
Puppet 是一个用于配置和维护计算机的工具;通过使用 puppet 的简单的配置语言,你可以告诉 Puppet,你希望如何配置机器,然后 Puppet 就会按照你的指示来修改机器的配置。之后,如果你改变了需求,比如更新了软件包,增加了新用户,或是更新了配置,那么 Puppet 也会自动地随之更新你的机器。而如果这些机器本来就已经配置好了,Puppet 就什么都不会动。
总的讲,Puppet 可以借助任何已有的系统特性来完成它的工作。比如,在 Red Hat 中,它会使用yum 来进行包管理,并修改 init.d 来管理系统服务;而在 OS X 中,Puppet 则使用 dmg 来管理软件包,使用 launchd 来管理系统服务。Puppet 的一个目标就是让你或者系统本身都可以通过 Puppet 代码来明白如何进行工作,所以,必须要能够遵从各个系统的规范。
Puppet 集成了很多已有工具的传统。从开源社区的角度讲,对 Puppet 影响最大的莫过于 CF-Engine 和 ISconf 了,CF-Engine 是第一个开源通用配置管理工具,而 ISconf 使用了 make 来完成所用工作,其灵感来源于显式地处理系统中所有的依赖关系。在商业软件中,Puppet 受到了 BladeLogic 和 Opsware (两者都已经被大公司收购了)的影响,在 Puppet 项目开始时,这两种工具都在市场中获得了不小的成功,不过两者都更加关注于向大公司的管理层来推销,相反,对于直接为管理员提供一个强大的工具,没有足够的重视。Puppet 希望和这些工具解决差不多的问题,但关注的用户有很大不同。
这个简单的例子用于解释如何使用 Puppet,例子中的这段代码用来确保系统中安装了 SSH 服务,并配置正确:
class ssh {
package { ssh: ensure => installed }
file { "/etc/ssh/sshd_config":
source => 'puppet:///modules/ssh/sshd_config',
ensure => present,
require => Package[ssh]
}
service { sshd:
ensure => running,
require => [File["/etc/ssh/sshd_config"], Package[ssh]]
}
}这个配置确保软件包被安装,文件就位,并且服务运行。注意,我们指定了资源之间的依赖关系,这样,我们就可以确保一定能够按照正确顺序工作。这个类 (class) 可以被关联到任何一个需要这个配置的主机。Puppet 配置的基本组件是结构化的对象,在这个例子里就是 package, file 和service。我们将这些对象称为资源 (resource),Puppet 配置中的任何东西,最后都会分解为一些资源,以及资源间的依赖关系。
通常,一个使用 Puppet 的机构可能拥有数十甚至上百个这样的代码段,我们称之为类 (class),我们将存储这些类的文件称为货单 (manifest),这些被按照相关性分组,这些组称为模块 (module)。比如,你可能有个 ssh 模块,其中包含了这个 ssh 类和一些其他相关类,同时还会有诸如 mysql,apache, 以及 sudo 等模块。
大部分的 Puppet 交互都通过命令行或是一直运行着的 HTTP 服务进行的,不过有些东西也有图形界面,比如报告处理。Puppet Labs 还提供了一些 Puppet 的周边商业产品,这些产品更倾向于使用基于 web 的图形化界面。
Puppet 的第一个原型写于2004年夏天,从2005年2月开始成为了一个有全职投入的项目。Puppet 最初由 Luke Kanies 设计并实现,它是一位经验丰富、写过很多不足万行的小工具的管理员。本质上说,随着 Puppet 的开发,Luke 学着称为了一位程序员,从程序架构上说,这具有正反两面性。
Puppet 最初并最重要的目的就是成为一个管理员的工具,让他们的工作更轻松、更快、更高效,且更不易犯错。第一个关键性的创新就是上面提到的资源,这是 Puppet 的基本元素,它们是跨操作系统可移植的,并且抽象的资源屏蔽了实现细节,允许用户关注配置的结果,而非具体如何实现这些配置。而这些基本元素本身由 Puppet 的资源抽象层来实现。
在一台给定的主机上,Puppet 资源必须是唯一的。你只能有一个叫 "ssh" 的包,一个叫 "sshd" 的服务,也只能有一个叫 "/etc/ssh/sshd_config" 的文件。这就避免了你的配置的不同部分之间的冲突,一旦发生冲突,你会在进行配置的最初阶段发现它。我们可以通过资源的名称和类型来指定一个资源,比如 Package[ssh] 和 Service[sshd]。你可以有一个包和一个服务同名,因为它们类型不同,但不论如何,你都不可以有两个同名的包或是同名的服务。
Puppet 的第二个重要创新是提供了一种方法,来直接指定资源之间的依赖关系。之前的各种工具的关注点都在于某个孤立的工作是否完成,而非它们之间的各种关联性;Puppet 是第一种明确地将依赖关系作为配置中的一等元素的工具,而且,必须在建模中明确指出依赖型。Puppet 会根据资源及其依赖型构建出一张图,在 Puppet 的执行过程中,每件事情都对应于这张图(称为目录, Catalog)和图的顶点与边。
Puppet 的最后一个重要组成部分是它的配置语言。这是一种声明性的语言,其重点在于配置数据,而非编程。很大程度上说,它沿袭了 Nagios 的配置格式,不过也受到了 CFEngine 和 Ruby 的很大影响。
除了功能性组件之外,在 Puppet 开发过程中,还有两个指导性原则:简单胜过一切,易用性胜于能力;先做框架,再做应用,其他人可以在 Puppet 的基础上开发它们自己的应用。可以这么理解,Puppet 框架需要一个杀手级的应用(Puppet 本身)来让自己获得广泛接受,但框架始终是关注的焦点,而非应用。当然,大部分人开始会将 Puppet 作为一个应用来使用,而非其背后的框架。
当 Puppet 的原型刚刚搭建出来时,Luke 还是一个 Perl 程序员,也有不少 shell 经验以及一些 C 的经验,主要使用 CFEngine 工作。不寻常的一点是,他拥有为简单语言写解析器的经验,曾经为一些小工具写过解析器部分,也从头重写过 CFEngine 的解析器,来让它更容易维护(这段代码从未被提交到上游项目中去,因为有些小的兼容性问题)。
对于 Puppet 的实现,选择一个动态语言是没什么争议的,因为动态语言的开发效率会更高,但是选择一个合适的语言却十分困难。最初的使用 Perl 的原型不是非常好用,所以 Luke 开始考虑其他语言。Python 曾经被考察过,但 Luke 发现这种语言和他的世界观不够匹配。在朋友的关于语言易用性的言论影响下,Luke 尝试了 Ruby,4小时之后,他就使用 Ruby 完成了一个可用的原型。在2005年,当 Puppet 成为 Luke 的全职项目时,Ruby 还是一种默默无闻的语言,这个决定显然有巨大的风险,程序员的开发效率是选择 Ruby 的决定性因素。相对于 Perl,Ruby 的最显著的特性是,非常容易构建非层次式的(non-hierarchical)类间关系,这和 Luke 所想的非常匹配,这之后被证明是决定性的(critical)。
18.2. 架构概览
本章主要讨论 Puppet 的实现架构(也就是我们用来让 Puppet 来完成我们想让它进行的工作的代码),不过,简要探讨一下应用架构(也就是程序的各个部分之间如何通信)也会很有帮助,这会让我们对实现有所感觉。
Puppet 支持两种工作模式:客户机/服务器模式,由一个中心服务器和部署到各个主机上的代理(agent)构成;或无服务器模式(serverless),由一个单独的进程完成所有工作。为了确保这些模式之间的一致性,Puppet 内部始终是对网络透明的,这样,两种模式可以使用相同的代码,只是是否走网络有所不同。每个可执行程序都可以根据需要配置使用本地或远程服务,除此之外,它们的行为都是完全一致的。注意,你也可以在进行客户机/服务器使用的情况下使用无服务器模式,只要将所有配置文件推送到每个客户端上,并让它们直接解析这些文件即可。本节将集中在客户机/服务器模式上,因为这样更易于把各个功能理解为彼此独立的组件,不过请各位明白,这些实际上在无服务器模式下也是同样的。
Puppet 架构上的一个设计决策是,认为客户端不应该直接访问到 Puppet 模块;相反,它们应该得到专为它们编译的配置。这样做有很多好处:首先,这遵从了最小权限准则,每台主机只能得到它自己需要知道的(它该如何配置自己),不会知道其他服务器如何配置。其次,你可以将编译配置的权限(需要访问中央数据存储)和实施配置的权限彼此分离。第三,当主机之后每次应用配置的时候,可以处于离线状态,无需与中央服务器保持连接,这意味着即使是服务器当即了,或者两者无法连接了(比如,移动客户端,或是客户端位于DMZ中等),也可以重复应用配置。
这样,Puppet 的工作流就比较直接了:
- Puppet 代理进程收集当前主机的信息,并交给服务器。
- 解析器利用系统信息和磁盘上存储的模块信息,编译为对这台机器的一个配置信息,并将这些配置信息返回给代理。
- 代理将配置应用到本地主机,这将影响主机的本地状态,之后,将结果状态汇报给服务器。
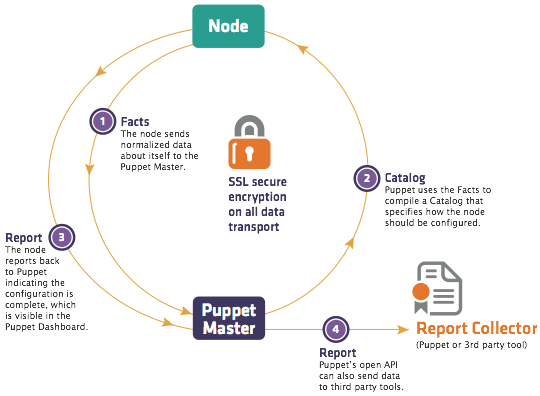
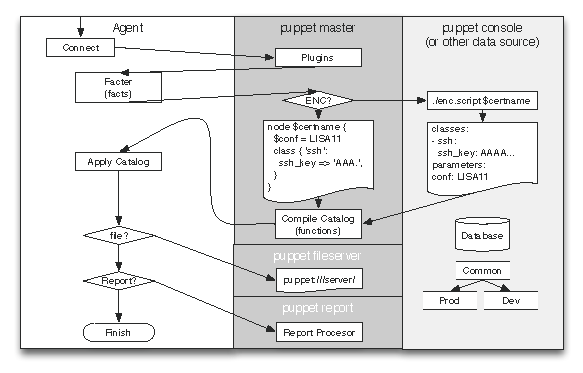
这样,代理拥有访问它自己的系统信息、配置、以及它自己生成的报告的权限。服务器拥有这些数据的副本,还有访问所有 Puppet 模块、后端数据库和可能用于编译配置信息的服务的权限。
这个工作流图中的组件之外,我们后面还会用到很多 Puppet 用来进行内部通信的数据类型。这些数据类型非常重要,因为这些数据中有些是决定了各种通信如何进行,有些公开类型影响到其他工具如何产生或使用这些与 Puppet 交互的数据。
最重要的数据类型包括:
- Facts: 从每台机器上收集到的系统数据,用于编译为配置。
- Manifest: 包含 Puppet 代码的文件,通常被组织为一些称为“模块 (modules)”的集合中。
- Catalog: 一张包含主机上可管理资源及其依赖关系的图。
- Report: 对于一个 Catalog,在其应用过程中产生的所有事件的集合。
在 Facts, Manifests, Catalogs, 和 Reports 之外,Puppet 还支持 files, certificates (用于鉴权)等服务类型。


更多建议: