
 免费 AI IDE
免费 AI IDE

NumPy 屏蔽数组
本篇教程适用于对 NumPy 有基本了解并希望了解如何numpy.ma在实践中使用掩码数组和模块的人。
学习目标
完成本教程后,您应该能够:
- 了解什么是屏蔽数组以及如何创建它们
- 了解如何访问和修改掩码数组的数据
- 决定在您的某些应用程序中何时适合使用掩码数组
什么是屏蔽数组?
考虑以下问题。您有一个包含缺失或无效条目的数据集。如果您正在对这些数据进行任何类型的处理,并且想要 跳过或标记这些不需要的条目而不只是删除它们,您可能必须使用条件或以某种方式过滤您的数据。该numpy.ma模块提供了一些与添加结构相同的功能 ,以确保在计算中不使用无效条目。NumPy ndarrays
来自:Reference Guide
掩码数组是标准numpy.ndarray和掩码的组合。掩码要么是nomask,表示关联数组的任何值都无效,要么是布尔数组,用于确定关联数组的每个元素的值是否有效。当掩码False的元素为 时,关联数组的对应元素是有效的,称为未掩码。当掩码True的元素为 时,关联数组的对应元素被称为被掩码(无效)。
我们可以将 aMaskedArray视为以下各项的组合:
- 数据,作为
numpy.ndarray任何形状或数据类型的正则; - 与数据形状相同的布尔掩码;
- A
fill_value,可用于替换无效条目以返回标准的值numpy.ndarray。
它们什么时候有用?
在某些情况下,屏蔽数组比仅仅消除数组的无效条目更有用:
- 当您想保留您屏蔽的值以供以后处理时,而不复制数组;
- 当您必须处理许多数组时,每个数组都有自己的掩码。如果掩码是数组的一部分,则可以避免错误并且代码可能更紧凑;
- 当您对缺失值或无效值有不同的标志时,并希望保留这些标志而不在原始数据集中替换它们,但将它们从计算中排除;
- 如果您无法避免或消除缺失值,但又不想在操作中处理
NaN(Not A Number) 值。
屏蔽数组也是一个好主意,因为该numpy.ma模块还附带了大多数NumPy 通用函数 (ufuncs)的特定实现,这意味着您仍然可以对屏蔽数据应用快速矢量化函数和操作。输出然后是一个掩码数组。我们将在下面的实践中看到一些示例,说明它是如何工作的。
使用掩码数组查看 COVID-19 数据
可以从Kaggle下载数据集,其中包含有关 2020 年初 COVID-19 爆发的初始数据。我们将查看文件中包含的一小部分数据who_covid_19_sit_rep_time_series.csv。
In [1]: import numpy as np
In [2]: import os
## The os.getcwd() function returns the current folder; you can change
## the filepath variable to point to the folder where you saved the .csv file
In [3]: filepath = os.getcwd()
In [4]: filename = os.path.join(filepath, "who_covid_19_sit_rep_time_series.csv")数据文件包含不同类型的数据,组织如下:
- 第一行是标题行,(主要)描述了下面各行中每列中的数据,从第四列开始,标题是观察日期。
- 第二行到第七行包含与我们将要检查的数据类型不同的汇总数据,因此我们需要将其从我们将使用的数据中排除。
- 我们希望处理的数值数据从第 4 列第 8 行开始,并从那里延伸到最右侧的列和最下方的行。
让我们探索该文件中前 14 天记录的数据。为了从.csv文件中收集数据,我们将使用该numpy.genfromtxt 函数,确保我们只选择具有实际数字的列,而不是包含位置数据的前三列。我们也跳过这个文件的前 7 行,因为它们包含我们不感兴趣的其他数据。我们将分别提取这些数据的日期和位置信息。
## Note we are using skip_header and usecols to read only portions of the
## data file into each variable.
## Read just the dates for columns 3-7 from the first row
In [5]: dates = np.genfromtxt(filename, dtype=np.unicode_, delimiter=",",
...: max_rows=1, usecols=range(3, 17),
...: encoding="utf-8-sig")
...:
## Read the names of the geographic locations from the first two
## columns, skipping the first seven rows
In [6]: locations = np.genfromtxt(filename, dtype=np.unicode_, delimiter=",",
...: skip_header=7, usecols=(0, 1),
...: encoding="utf-8-sig")
...:
## Read the numeric data from just the first 14 days
In [7]: nbcases = np.genfromtxt(filename, dtype=np.int_, delimiter=",",
...: skip_header=7, usecols=range(3, 17),
...: encoding="utf-8-sig")
...: 包括在numpy.genfromtxt函数调用中,我们 numpy.dtype为数据的每个子集(整数 - numpy.int_- 或字符串 - numpy.unicode_)选择了 。我们还使用encoding参数选择utf-8-sig作为文件的编码(在官方 Python 文档中阅读更多关于编码的信息)。您可以numpy.genfromtxt从或 基本 IO 教程中阅读有关该函数的更多信息。Reference Documentation
探索数据
首先,我们可以绘制我们拥有的整个数据集,看看它是什么样子。为了获得可读的图,我们只选择了几个日期显示在我们的. 还要注意,在我们的绘图命令中,我们使用(数组的转置),因为这意味着我们将文件的每一行作为单独的行绘制。我们选择绘制一条虚线(使用线型)。有关这方面的更多信息,请参阅 matplotlib文档。x-axis ticks``nbcases.T``nbcases``'--'
In [8]: import matplotlib.pyplot as plt
In [9]: selected_dates = [0, 3, 11, 13]
In [10]: plt.plot(dates, nbcases.T, '--');
In [11]: plt.xticks(selected_dates, dates[selected_dates]);
In [12]: plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020");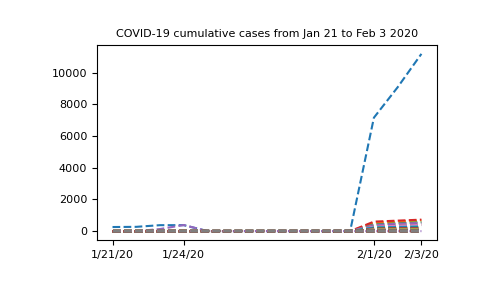
笔记
如果您在 IPython shell 中执行上述命令,则可能需要使用该命令plt.show()来显示图像窗口。另请注意,我们在行尾使用分号来抑制其输出,但这是可选的。
该图从 1 月 24 日到 2 月 1 日具有奇怪的形状。知道这些数据来自哪里会很有趣。如果我们查看locations 从.csv文件中提取的数组,我们可以看到我们有两列,其中第一列包含地区,第二列包含国家名称。但是,只有前几行包含第一列的数据(中国的省名)。之后,我们只有国家/地区名称。因此,将来自中国的所有数据分组为一行是有意义的。为此,我们将从nbcases数组中仅选择数组的第二个条目locations对应于中国的行。接下来,我们将使用该numpy.sum函数对所有选定的行 ( axis=0)求和:
In [13]: china_total = nbcases[locations[:, 1] == 'China'].sum(axis=0)
In [14]: china_total
Out[14]:
array([ 247, 288, 556, 817, -22, -22, -15, -10, -9,
-7, -4, 11820, 14410, 17237])这个数据有问题 - 我们不应该在累积数据集中有负值。这是怎么回事?
缺失数据
查看数据,我们发现:有一段 数据缺失:
In [15]: nbcases
Out[15]:
array([[ 258, 270, 375, ..., 7153, 9074, 11177],
[ 14, 17, 26, ..., 520, 604, 683],
[ -1, 1, 1, ..., 422, 493, 566],
...,
[ -1, -1, -1, ..., -1, -1, -1],
[ -1, -1, -1, ..., -1, -1, -1],
[ -1, -1, -1, ..., -1, -1, -1]])-1我们看到的所有值都来自numpy.genfromtxt 尝试从原始.csv文件中读取丢失的数据。显然,我们不想计算丢失的数据-1——我们只想跳过这个值,这样它就不会干扰我们的分析。导入numpy.ma 模块后,我们将创建一个新数组,这次屏蔽无效值:
In [16]: from numpy import ma
In [17]: nbcases_ma = ma.masked_values(nbcases, -1)如果我们查看nbcases_ma掩码数组,这就是我们所拥有的:
In [18]: nbcases_ma
Out[18]:
masked_array(
data=[[258, 270, 375, ..., 7153, 9074, 11177],
[14, 17, 26, ..., 520, 604, 683],
[--, 1, 1, ..., 422, 493, 566],
...,
[--, --, --, ..., --, --, --],
[--, --, --, ..., --, --, --],
[--, --, --, ..., --, --, --]],
mask=[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[ True, False, False, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
fill_value=-1)我们可以看到这是一种不同的数组。正如介绍中提到的,它具有三个属性(data、mask和fill_value)。请记住,该mask属性具有True对应于无效数据的元素的值(由data 属性中的两个破折号表示)。
笔记
添加-1丢失的数据不是问题numpy.genfromtxt;在这种特殊情况下,用 替换缺失值0可能没问题,但我们稍后会看到这远非通用解决方案。此外,可以numpy.genfromtxt使用usemask参数调用该函数 。如果usemask=True,numpy.genfromtxt 自动返回一个掩码数组。
让我们试着看看排除第一行(中国湖北省的数据)后的数据是什么样的,以便我们可以更仔细地查看缺失的数据:
In [19]: plt.plot(dates, nbcases_ma[1:].T, '--');
In [20]: plt.xticks(selected_dates, dates[selected_dates]);
In [21]: plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020");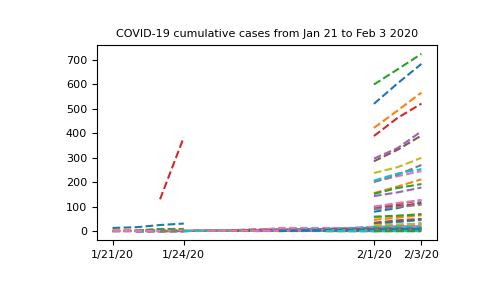
现在我们的数据已经被屏蔽了,让我们尝试总结一下中国的所有案例:
In [22]: china_masked = nbcases_ma[locations[:, 1] == 'China'].sum(axis=0)
In [23]: china_masked
Out[23]:
masked_array(data=[278, 309, 574, 835, 10, 10, 17, 22, 23, 25, 28, 11821,
14411, 17238],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value=999999)请注意,这china_masked是一个掩码数组,因此它具有与常规 NumPy 数组不同的数据结构。现在,我们可以使用.data属性直接访问其数据:
In [24]: china_total = china_masked.data
In [25]: china_total
Out[25]:
array([ 278, 309, 574, 835, 10, 10, 17, 22, 23,
25, 28, 11821, 14411, 17238])那更好:没有更多的负值。但是,我们仍然可以看到,有几天,病例的累计数量似乎在下降(例如从 835 件减少到 10 件),这与“累计数据”的定义不符。如果我们仔细看数据,我们可以看到,在中国大陆数据缺失的时期,香港、台湾、澳门和中国“未指定”地区的数据是有效的。也许我们可以从中国的病例总数中去除这些,以便更好地了解数据。
首先,我们将确定中国大陆地区的位置索引:
In [26]: china_mask = ((locations[:, 1] == 'China') &
....: (locations[:, 0] != 'Hong Kong') &
....: (locations[:, 0] != 'Taiwan') &
....: (locations[:, 0] != 'Macau') &
....: (locations[:, 0] != 'Unspecified*'))
....: 现在,china_mask是一个布尔值数组(True或False);我们可以使用ma.nonzero掩码数组的方法检查索引是否是我们想要的:
In [27]: china_mask.nonzero()
Out[27]:
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 25, 26, 27, 28, 29, 31, 33]),)现在我们可以正确总结中国大陆的条目:
In [28]: china_total = nbcases_ma[china_mask].sum(axis=0)
In [29]: china_total
Out[29]:
masked_array(data=[278, 308, 440, 446, --, --, --, --, --, --, --, 11791,
14380, 17205],
mask=[False, False, False, False, True, True, True, True,
True, True, True, False, False, False],
fill_value=999999)我们可以用这些信息替换数据并绘制一个新的图表,重点是中国大陆:
In [30]: plt.plot(dates, china_total.T, '--');
In [31]: plt.xticks(selected_dates, dates[selected_dates]);
In [32]: plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China");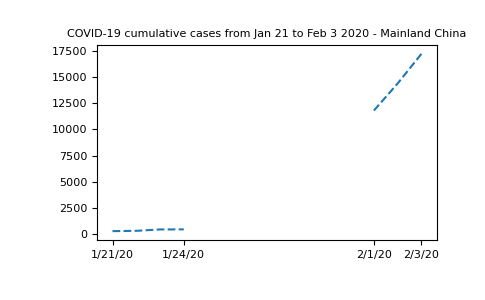
很明显,屏蔽数组是这里的正确解决方案。我们不能在不错误描述曲线演变的情况下表示缺失的数据。
拟合数据
我们可以想到的一种可能性是对缺失的数据进行插值,以估计 1 月下旬的病例数。观察到我们可以使用.mask属性选择被屏蔽的元素:
In [33]: china_total.mask
Out[33]:
array([False, False, False, False, True, True, True, True, True,
True, True, False, False, False])
In [34]: invalid = china_total[china_total.mask]
In [35]: invalid
Out[35]:
masked_array(data=[--, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True],
fill_value=999999,
dtype=int64)我们还可以通过使用此掩码的逻辑否定来访问有效条目:
In [36]: valid = china_total[~china_total.mask]
In [37]: valid
Out[37]:
masked_array(data=[278, 308, 440, 446, 11791, 14380, 17205],
mask=[False, False, False, False, False, False, False],
fill_value=999999)现在,如果我们想为这些数据创建一个非常简单的近似值,我们应该考虑无效条目周围的有效条目。所以首先让我们选择数据有效的日期。请注意,我们可以使用china_total掩码数组中的掩码来索引日期数组:
In [38]: dates[~china_total.mask]
Out[38]:
array(['1/21/20', '1/22/20', '1/23/20', '1/24/20', '2/1/20', '2/2/20',
'2/3/20'], dtype='<U7')最后,我们可以使用numpy.polyfit和numpy.polyval 函数来创建尽可能适合数据的三次多项式:
In [39]: t = np.arange(len(china_total))
In [40]: params = np.polyfit(t[~china_total.mask], valid, 3)
In [41]: cubic_fit = np.polyval(params, t)
In [42]: plt.plot(t, china_total);
In [43]: plt.plot(t, cubic_fit, '--');
这个情节不太可读,因为线条似乎相互重叠,所以让我们用一个更详细的情节来总结。我们将在可用时绘制真实数据,并显示不可用数据的三次拟合,使用此拟合计算对 2020 年 1 月 28 日(记录开始后 7 天)观察到的病例数的估计:
In [44]: plt.plot(t, china_total, label='Mainland China');
In [45]: plt.plot(t[china_total.mask], cubic_fit[china_total.mask], '--',
....: color='orange', label='Cubic estimate');
....:
In [46]: plt.plot(7, np.polyval(params, 7), 'r*', label='7 days after start');
In [47]: plt.xticks([0, 7, 13], dates[[0, 7, 13]]);
In [48]: plt.yticks([0, np.polyval(params, 7), 10000, 17500]);
In [49]: plt.legend();
In [50]: plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China\n"
....: "Cubic estimate for 7 days after start");
....: 


更多建议: