
 免费 AI IDE
免费 AI IDE

详解慢查询
查询mysql的操作信息
show status -- 显示全部mysql操作信息
show status like "com_insert%"; -- 获得mysql的插入次数;
show status like "com_delete%"; -- 获得mysql的删除次数;
show status like "com_select%"; -- 获得mysql的查询次数;
show status like "uptime"; -- 获得mysql服务器运行时间
show status like 'connections'; -- 获得mysql连接次数show [session|global] status like .... 如果你不写 [session|global] 默认是session 会话,只取出当前窗口的执行,如果你想看所有(从mysql 启动到现在,则应该 global)
通过查询mysql的读写比例,可以做相应的配置优化;
慢查询
当Mysql性能下降时,通过开启慢查询来获得哪条SQL语句造成的响应过慢,进行分析处理。当然开启慢查询会带来CPU损耗与日志记录的IO开销,所以我们要间断性的打开慢查询日志来查看Mysql运行状态。
慢查询能记录下所有执行超过long_query_time时间的SQL语句, 用于找到执行慢的SQL, 方便我们对这些SQL进行优化.
show variables like "%slow%";-- 是否开启慢查询;
show status like "%slow%"; -- 查询慢查询SQL状况;
show variables like "long_query_time"; -- 慢查询时间慢查询开启设置
mysql> show variables like 'long_query_time'; -- 默认情况下,mysql认为10秒才是一个慢查询
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
mysql> set long_query_time=1; -- 修改慢查询时间,只能当前会话有效;
mysql> set global slow_query_log='ON';-- 启用慢查询 ,加上global,不然会报错的;也可以在配置文件中更改
修改mysql配置文件my.ini[windows]/my.cnf[Linux]加入,注意必须在[mysqld]后面加入
slow_query_log = on -- 开启日志;
slow_query_log_file = /data/f/mysql_slow_cw.log -- 记录日志的log文件; 注意:window上必须写绝对路径,比如 D:/wamp/bin/mysql/mysql5.5.16/data/show-slow.log
long_query_time = 2 -- 最长查询的秒数;
log-queries-not-using-indexes -- 表示记录没有使用索引的查询使用慢查询
Example1:
mysql> select sleep(3);
mysql> show status like '%slow%';
+---------------------+-------+
| Variable_name | Value |
+---------------------+-------+
| Slow_launch_threads | 0 |
| Slow_queries | 1 |
+---------------------+-------+
-- Slow_queries 一共有一条慢查询Example2:
利用存储过程构建一个大的数据库来进行测试;
数据准备
CREATE TABLE dept(
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 comment '编号',
dname VARCHAR(20) NOT NULL DEFAULT "" comment '名称',
loc VARCHAR(13) NOT NULL DEFAULT "" comment '地点'
) ENGINE=MyISAM DEFAULT CHARSET=utf8 comment '部门表' ;
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
ename VARCHAR(20) NOT NULL DEFAULT "" comment '名字',
job VARCHAR(9) NOT NULL DEFAULT "" comment '工作',
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 comment '上级编号',
hiredate DATE NOT NULL comment '入职时间',
sal DECIMAL(7,2) NOT NULL comment '薪水',
comm DECIMAL(7,2) NOT NULL comment '红利',
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 comment '部门编号'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 comment '雇员表';
CREATE TABLE salgrade(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 comment '等级',
losal DECIMAL(17,2) NOT NULL comment '最低工资',
hisal DECIMAL(17,2) NOT NULL comment '最高工资'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 comment '工资级别表';
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $
create function rand_num()
returns tinyint(6) READS SQL DATA
begin
declare return_num tinyint(6) default 0;
set return_num = floor(1+rand()*30);
return return_num;
end $
delimiter $
create function rand_string(n INT)
returns varchar(255) READS SQL DATA
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $
delimiter $
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0,关闭自动提交;
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $
call insert_emp(1,4000000);SELECT * FROM `emp` where ename like '%mQspyv%'; -- 1.163s
# Time: 150530 15:30:58 -- 该查询发生在2015-5-30 15:30:58
# User@Host: root[root] @ localhost [127.0.0.1] -- 是谁,在什么主机上发生的查询
# Query_time: 1.134065 Lock_time: 0.000000 Rows_sent: 8 Rows_examined: 4000000
-- Query_time: 查询总共用了多少时间,Lock_time: 在查询时锁定表的时间,Rows_sent: 返回多少rows数据,Rows_examined: 表扫描了400W行数据才得到的结果;
SET timestamp=1432971058; -- 发生慢查询时的时间戳;
SELECT * FROM `emp` where ename like '%mQspyv%';开启慢查询后每天都有可能有好几G的慢查询日志,这个时候去人工的分析明显是不实际的;
慢查询分析工具:
mysqldumpslow
该工具是慢查询自带的分析慢查询工具,一般只要安装了mysql,就会有该工具;
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ] -- 后跟参数以及log文件的绝对地址;
-s what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time常见用法
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log # 取出使用最多的10条慢查询
mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log # 取出查询时间最慢的3条慢查询
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log # 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s r -t 10 -g 'left join' /var/run/mysqld/mysqld-slow.log # 按照扫描行数最多的注意: 使用mysqldumpslow的分析结果不会显示具体完整的sql语句,只会显示sql的组成结构;
假如: SELECT * FROM sms_send WHERE service_id=10 GROUP BY content LIMIT 0, 1000;
mysqldumpslow来显示
Count: 1 Time=1.91s (1s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N;pt-query-digest
说明
pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
pt-query-digest是一个perl脚本,只需下载并赋权即可执行。
安装
wget http://www.percona.com/get/pt-query-digest
chmod +x pt-query-digest
# 注意这是一个Linux脚本,要指明绝对或相对路径来使用
--或者下载整套工具
wget percona.com/get/percona-toolkit.rpm
rpm -ivh percona-toolkit-2.2.13-1.noarch.rpm
wget percona.com/get/percona-toolkit.tar.gz
tar -zxvf percona-toolkit-2.2.13.tar.gz
cd percona-toolkit-2.2.13
perl Makefile.PL
make && make install语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]
--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。
--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。
--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
--limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
--host mysql服务器地址
--user mysql用户名
--password mysql用户密码
--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。
--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
--until 截止时间,配合—since可以分析一段时间内的慢查询。第一部分:总体统计结果:
标准分析报告解释
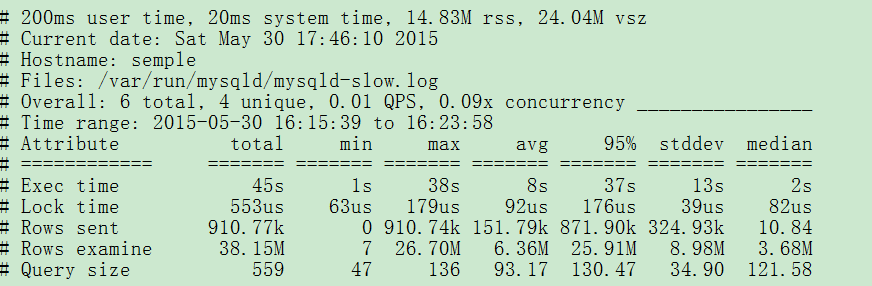
Overall: 总共有多少条查询,上例为总共266个查询。
Time range: 查询执行的时间范围。
unique: 唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询,该例为4。
total: 总计 min:最小 max: 最大 avg:平均
95%: 把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值。
median: 中位数,把所有值从小到大排列,位置位于中间那个数。
第二部分: 查询分组统计结果:
这部分对查询进行参数化并分组,然后对各类查询的执行情况进行分析,结果按总执行时长,从大到小排序。
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
第三部分:每一种查询的详细统计结果: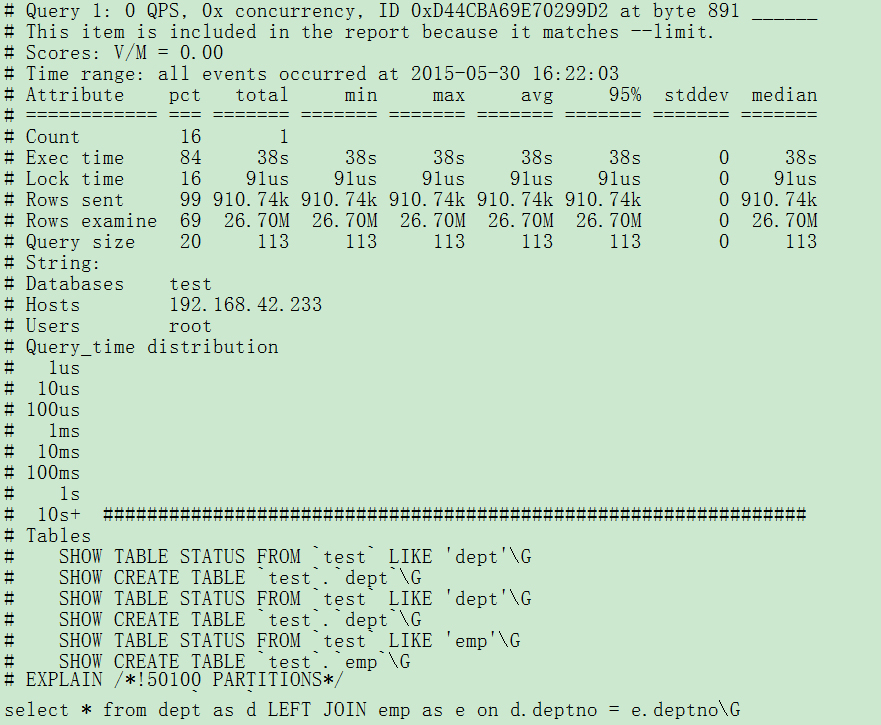
由上图可见,1号查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
Databases: 库名
Users: 各个用户执行的次数(占比)
Query_time distribution : 查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量没有,全部集中在10S里面。
Tables: 查询中涉及到的表
Explain: 该条查询的示例
用法示例
(1)直接分析慢查询文件:
pt-query-digest slow.log > slow_report.log(2)分析最近12小时内的查询:
pt-query-digest --since=12h slow.log > slow_report2.log(3)分析指定时间范围内的查询:
pt-query-digest slow.log --since '2014-05-17 09:30:00' --until '2014-06-17 10:00:00'> > slow_report3.log(4)分析只含有select语句的慢查询
pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' slow.log> slow_report4.log(5) 针对某个用户的慢查询
pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log> slow_report5.log(6) 查询所有所有的全表扫描或full join的慢查询
pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' slow.log> slow_report6.log(7)把查询保存到test数据库的query_review表,如果没有的话会自动创建;
pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_review --create-review-table slow.log(8)把查询保存到query_history表
pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_ history --create-review-table slow.log_20140401(9)通过tcpdump抓取mysql的tcp协议数据,然后再分析
tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt
pt-query-digest --type tcpdump mysql.tcp.txt> slow_report9.log(10)分析binlog
mysqlbinlog mysql-bin.000093 > mysql-bin000093.sql
pt-query-digest --type=binlog mysql-bin000093.sql > slow_report10.log(11)分析general log
pt-query-digest --type=genlog localhost.log > slow_report11.log另外,还有一款
Query-digest-UI监控慢可视化查询应用,后续再玩;


更多建议: