
Benchmarks
Benchmarks
Overview
A selection of image classification models were tested across multiple platforms to create a point of reference for the TensorFlow community. The Methodology section details how the tests were executed and has links to the scripts used.
Results for image classification models
InceptionV3 (arXiv:1512.00567), ResNet-50 (arXiv:1512.03385), ResNet-152 (arXiv:1512.03385), VGG16 (arXiv:1409.1556), and AlexNet were tested using the ImageNet data set. Tests were run on Google Compute Engine, Amazon Elastic Compute Cloud (Amazon EC2), and an NVIDIA® DGX-1™. Most of the tests were run with both synthetic and real data. Testing with synthetic data was done by using a tf.Variable set to the same shape as the data expected by each model for ImageNet. We believe it is important to include real data measurements when benchmarking a platform. This load tests both the underlying hardware and the framework at preparing data for actual training. We start with synthetic data to remove disk I/O as a variable and to set a baseline. Real data is then used to verify that the TensorFlow input pipeline and the underlying disk I/O are saturating the compute units.
Training with NVIDIA® DGX-1™ (NVIDIA® Tesla® P100)
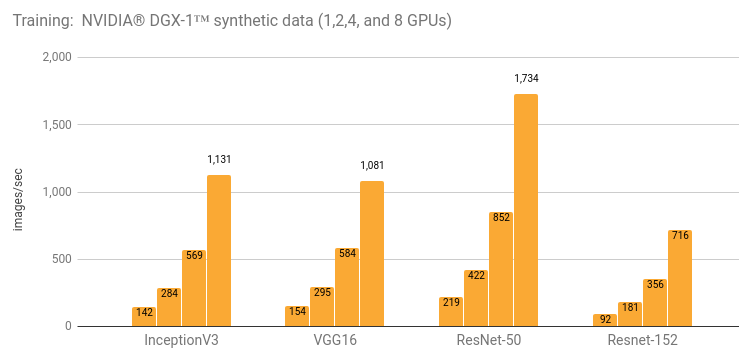
Details and additional results are in the Details for NVIDIA® DGX-1™ (NVIDIA® Tesla® P100) section.
Training with NVIDIA® Tesla® K80
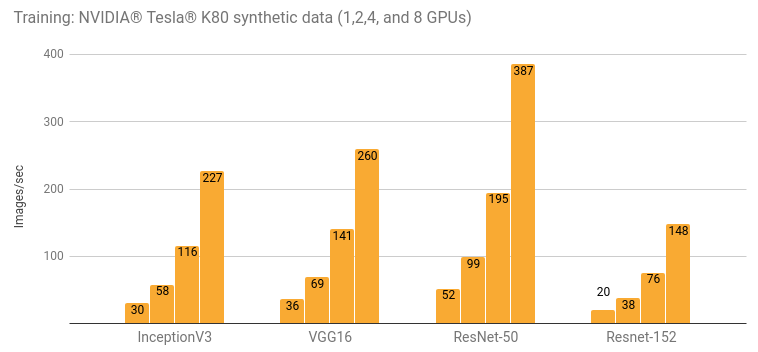
Details and additional results are in the Details for Google Compute Engine (NVIDIA® Tesla® K80) and Details for Amazon EC2 (NVIDIA® Tesla® K80) sections.
Distributed training with NVIDIA® Tesla® K80
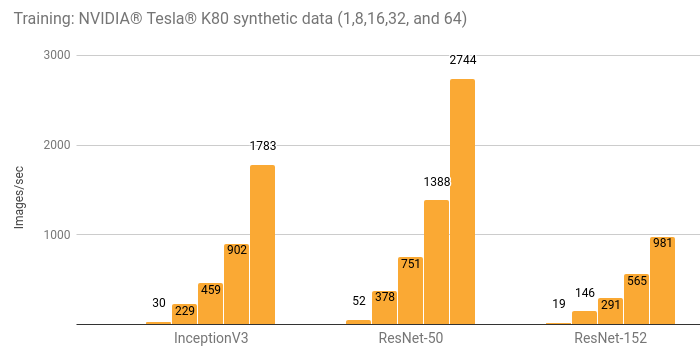
Details and additional results are in the Details for Amazon EC2 Distributed (NVIDIA® Tesla® K80) section.
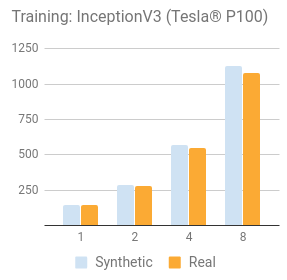
Compare synthetic with real data training
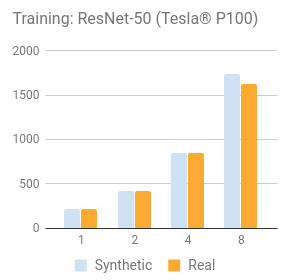
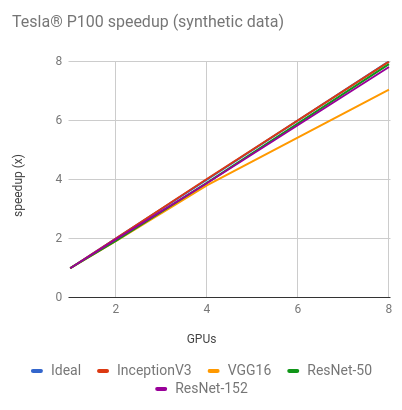
NVIDIA® Tesla® P100
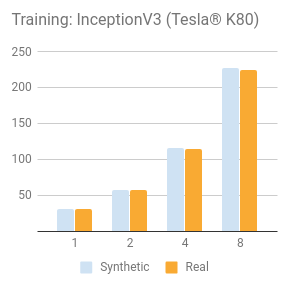
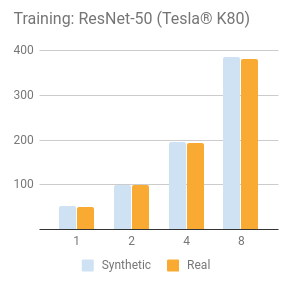
NVIDIA® Tesla® K80
Details for NVIDIA® DGX-1™ (NVIDIA® Tesla® P100)
Environment
- Instance type: NVIDIA® DGX-1™
- GPU: 8x NVIDIA® Tesla® P100
- OS: Ubuntu 16.04 LTS with tests run via Docker
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
-
Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: Local SSD
- DataSet: ImageNet
- Test Date: May 2017
Batch size and optimizer used for each model are listed in the table below. In addition to the batch sizes listed in the table, InceptionV3, ResNet-50, ResNet-152, and VGG16 were tested with a batch size of 32. Those results are in the other results section.
| Options | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 64 | 512 | 64 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
Configuration used for each model.
| Model | variable_update | local_parameter_device |
|---|---|---|
| InceptionV3 | parameter_server | cpu |
| ResNet50 | parameter_server | cpu |
| ResNet152 | parameter_server | cpu |
| AlexNet | replicated (with NCCL) | n/a |
| VGG16 | replicated (with NCCL) | n/a |
Results
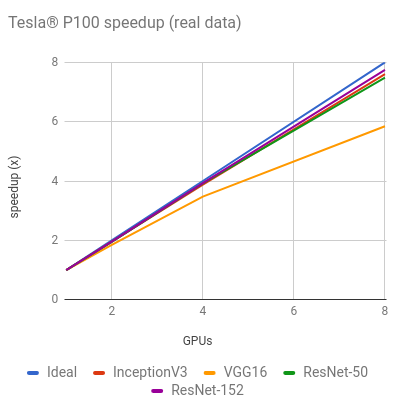
Training synthetic data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 142 | 219 | 91.8 | 2987 | 154 |
| 2 | 284 | 422 | 181 | 5658 | 295 |
| 4 | 569 | 852 | 356 | 10509 | 584 |
| 8 | 1131 | 1734 | 716 | 17822 | 1081 |
Training real data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 142 | 218 | 91.4 | 2890 | 154 |
| 2 | 278 | 425 | 179 | 4448 | 284 |
| 4 | 551 | 853 | 359 | 7105 | 534 |
| 8 | 1079 | 1630 | 708 | N/A | 898 |
Training AlexNet with real data on 8 GPUs was excluded from the graph and table above due to it maxing out the input pipeline.
Other Results
The results below are all with a batch size of 32.
Training synthetic data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 |
|---|---|---|---|---|
| 1 | 128 | 195 | 82.7 | 144 |
| 2 | 259 | 368 | 160 | 281 |
| 4 | 520 | 768 | 317 | 549 |
| 8 | 995 | 1485 | 632 | 820 |
Training real data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 |
|---|---|---|---|---|
| 1 | 130 | 193 | 82.4 | 144 |
| 2 | 257 | 369 | 159 | 253 |
| 4 | 507 | 760 | 317 | 457 |
| 8 | 966 | 1410 | 609 | 690 |
Details for Google Compute Engine (NVIDIA® Tesla® K80)
Environment
- Instance type: n1-standard-32-k80x8
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
-
Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1.7 TB Shared SSD persistent disk (800 MB/s)
- DataSet: ImageNet
- Test Date: May 2017
Batch size and optimizer used for each model are listed in the table below. In addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were tested with a batch size of 32. Those results are in the other results section.
| Options | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 | 512 | 32 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
The configuration used for each model was variable_update equal to parameter_server and local_parameter_device equal to cpu.
Results
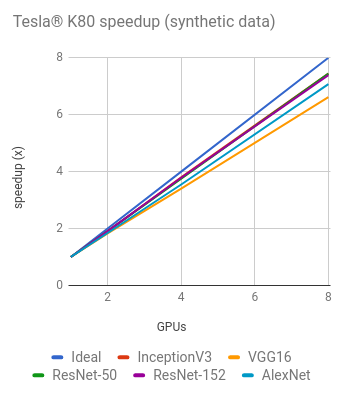
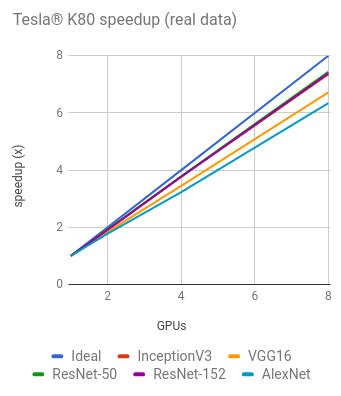
Training synthetic data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.5 | 51.9 | 20.0 | 656 | 35.4 |
| 2 | 57.8 | 99.0 | 38.2 | 1209 | 64.8 |
| 4 | 116 | 195 | 75.8 | 2328 | 120 |
| 8 | 227 | 387 | 148 | 4640 | 234 |
Training real data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.6 | 51.2 | 20.0 | 639 | 34.2 |
| 2 | 58.4 | 98.8 | 38.3 | 1136 | 62.9 |
| 4 | 115 | 194 | 75.4 | 2067 | 118 |
| 8 | 225 | 381 | 148 | 4056 | 230 |
Other Results
Training synthetic data
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.3 | 49.5 |
| 2 | 55.0 | 95.4 |
| 4 | 109 | 183 |
| 8 | 216 | 362 |
Training real data
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.5 | 49.3 |
| 2 | 55.4 | 95.3 |
| 4 | 110 | 186 |
| 8 | 216 | 359 |
Details for Amazon EC2 (NVIDIA® Tesla® K80)
Environment
- Instance type: p2.8xlarge
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
-
Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 MiB/sec)
- DataSet: ImageNet
- Test Date: May 2017
Batch size and optimizer used for each model are listed in the table below. In addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were tested with a batch size of 32. Those results are in the other results section.
| Options | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 | 512 | 32 |
| Optimizer | sgd | sgd | sgd | sgd | sgd |
Configuration used for each model.
| Model | variable_update | local_parameter_device |
|---|---|---|
| InceptionV3 | parameter_server | cpu |
| ResNet-50 | replicated (without NCCL) | gpu |
| ResNet-152 | replicated (without NCCL) | gpu |
| AlexNet | parameter_server | gpu |
| VGG16 | parameter_server | gpu |
Results
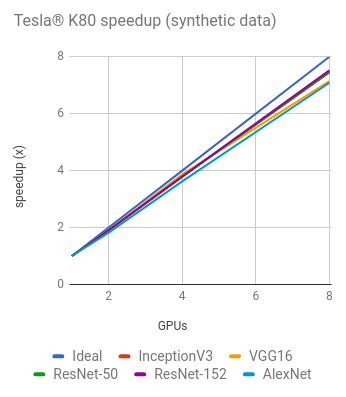
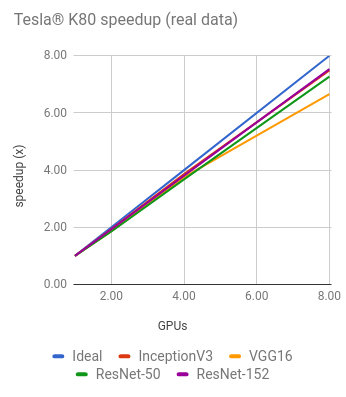
Training synthetic data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.8 | 51.5 | 19.7 | 684 | 36.3 |
| 2 | 58.7 | 98.0 | 37.6 | 1244 | 69.4 |
| 4 | 117 | 195 | 74.9 | 2479 | 141 |
| 8 | 230 | 384 | 149 | 4853 | 260 |
Training real data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.5 | 51.3 | 19.7 | 674 | 36.3 |
| 2 | 59.0 | 94.9 | 38.2 | 1227 | 67.5 |
| 4 | 118 | 188 | 75.2 | 2201 | 136 |
| 8 | 228 | 373 | 149 | N/A | 242 |
Training AlexNet with real data on 8 GPUs was excluded from the graph and table above due to our EFS setup not providing enough throughput.
Other Results
Training synthetic data
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.9 | 49.0 |
| 2 | 57.5 | 94.1 |
| 4 | 114 | 184 |
| 8 | 216 | 355 |
Training real data
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 30.0 | 49.1 |
| 2 | 57.5 | 95.1 |
| 4 | 113 | 185 |
| 8 | 212 | 353 |
Details for Amazon EC2 Distributed (NVIDIA® Tesla® K80)
Environment
- Instance type: p2.8xlarge
- GPU: 8x NVIDIA® Tesla® K80
- OS: Ubuntu 16.04 LTS
- CUDA / cuDNN: 8.0 / 5.1
- TensorFlow GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
-
Build Command:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package - Disk: 1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec)
- DataSet: ImageNet
- Test Date: May 2017
The batch size and optimizer used for the tests are listed in the table. In addition to the batch sizes listed in the table, InceptionV3 and ResNet-50 were tested with a batch size of 32. Those results are in the other results section.
| Options | InceptionV3 | ResNet-50 | ResNet-152 |
|---|---|---|---|
| Batch size per GPU | 64 | 64 | 32 |
| Optimizer | sgd | sgd | sgd |
Configuration used for each model.
| Model | variable_update | local_parameter_device | cross_replica_sync |
|---|---|---|---|
| InceptionV3 | distributed_replicated | n/a | True |
| ResNet-50 | distributed_replicated | n/a | True |
| ResNet-152 | distributed_replicated | n/a | True |
To simplify server setup, EC2 instances (p2.8xlarge) running worker servers also ran parameter servers. Equal numbers of parameter servers and worker servers were used with the following exceptions:
- InceptionV3: 8 instances / 6 parameter servers
- ResNet-50: (batch size 32) 8 instances / 4 parameter servers
- ResNet-152: 8 instances / 4 parameter servers
Results
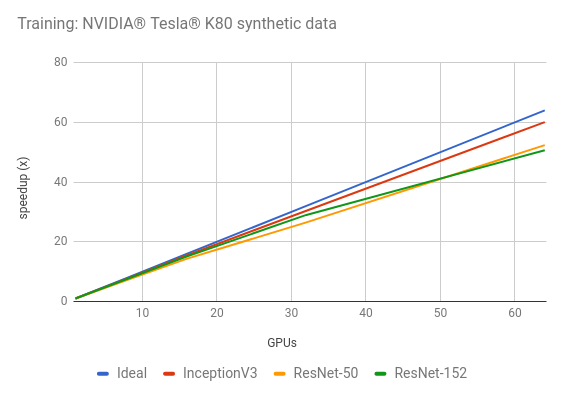
Training synthetic data
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 |
|---|---|---|---|
| 1 | 29.7 | 52.4 | 19.4 |
| 8 | 229 | 378 | 146 |
| 16 | 459 | 751 | 291 |
| 32 | 902 | 1388 | 565 |
| 64 | 1783 | 2744 | 981 |
Other Results
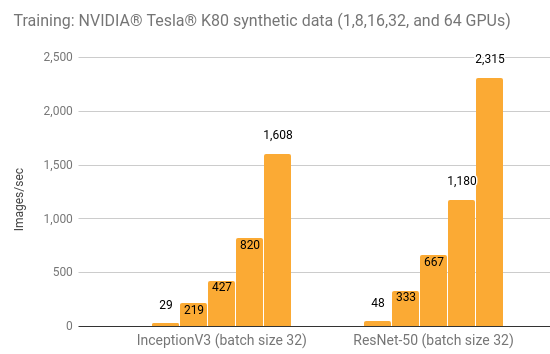
Training synthetic data
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.2 | 48.4 |
| 8 | 219 | 333 |
| 16 | 427 | 667 |
| 32 | 820 | 1180 |
| 64 | 1608 | 2315 |
Methodology
This script was run on the various platforms to generate the above results. High-Performance Models details techniques in the script along with examples of how to execute the script.
In order to create results that are as repeatable as possible, each test was run 5 times and then the times were averaged together. GPUs are run in their default state on the given platform. For NVIDIA® Tesla® K80 this means leaving on GPU Boost. For each test, 10 warmup steps are done and then the next 100 steps are averaged.
© 2017 The TensorFlow Authors. All rights reserved.
Licensed under the Creative Commons Attribution License 3.0.
Code samples licensed under the Apache 2.0 License.
https://www.tensorflow.org/performance/benchmarks


