
 免费 AI IDE
免费 AI IDE

一个最简单的网页是如何构成的
一个最最最简单的网页是怎么做出来的呢?首先我们先来简单的了解一下HTML语言,HTML是网络的通用语言,一种简单、通用的全置标记语言。HTML允许网页建设者建立文本与图片相结合的复杂页面,无论使用的是什么类型的电脑或浏览器,这些页面可以被网上任何所人浏览到。比如,你现在看到的就是这种语言写的页面。
如果你想深入学习HTML,可以参看w3cschool上的《HTML教程》
HTML的基本组成结构
3头部<head>······</head>:
<head> 标签用于定义文档的头部,它是所有头部元素的容器。<head> 中的元素可以引用脚本、指示浏览器在哪里找到样式表、提供元信息等等。
文档的头部描述了文档的各种属性和信息,包括文档的标题<title>。<title> 定义了文档的标题,它是 head 部分中唯一必需的元素。
在 Web 中的位置以及和其他文档的关系等。绝大多数文档头部包含的数据都不会真正作为内容显示给读者。
4、元标签<meta>
<meta> 元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。<meta> 标签位于文档的头部,不包含任何内容。
<meta> 标签永远位于 head 元素内部。
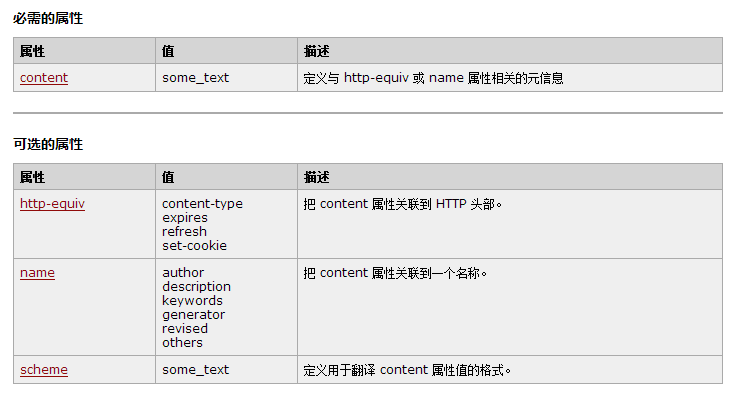
name 属性提供了名称/值对中的名称。HTML 和 XHTML 标签都没有指定任何预先定义的 <meta> 名称。通常情况下,您可以自由使用对自己和源文档的读者来说富有意义的名称。
"keywords" 是一个经常被用到的名称。它为文档定义了一组关键字。某些搜索引擎在遇到这些关键字时,会用这些关键字对文档进行分类。
类似这样的 meta 标签可能对于进入搜索引擎的索引有帮助:
<meta name="keywords" content="HTML,ASP,PHP,SQL">如果没有提供 name 属性,那么名称/值对中的名称会采用 http-equiv 属性的值。
http-equiv 属性
http-equiv 属性为名称/值对提供了名称。并指示服务器在发送实际的文档之前先在要传送给浏览器的 MIME 文档头部包含名称/值对。
当服务器向浏览器发送文档时,会先发送许多名称/值对。虽然有些服务器会发送许多这种名称/值对,但是所有服务器都至少要发送一个:content-type:text/html。这将告诉浏览器准备接受一个 HTML 文档。
使用带有 http-equiv 属性的 <meta> 标签时,服务器将把名称/值对添加到发送给浏览器的内容头部。例如,添加:
<meta http-equiv="charset" content="iso-8859-1">
<meta http-equiv="expires" content="31 Dec 2008">这样发送到浏览器的头部就应该包含:
content-type: text/html
charset:iso-8859-1
expires:31 Dec 2008当然,只有浏览器可以接受这些附加的头部字段,并能以适当的方式使用它们时,这些字段才有意义。
content 属性
content 属性提供了名称/值对中的值。该值可以是任何有效的字符串。
content 属性始终要和 name 属性或 http-equiv 属性一起使用。
scheme 属性
scheme 属性用于指定要用来翻译属性值的方案。此方案应该在由 <head> 标签的 profile 属性指定的概况文件中进行了定义。
5、眼睛<title>······</title>
就好像人的眼睛一样,它是心灵的窗口,而一个网页的眼睛应该就是它的页面的标题title了,我们都知道眼睛是长在头上的,所以,<title>标题</title>这些应放在<head>和</head>之间。也就是
<head><title>标题</title></head>6、身体<body>······</body>
身体body是网页最主要的部分了,因为上面写的那些东东网页是不显示出来的,而大家所看到的页面页就是身体部分了(当然它的TITLE可以在浏览器的最左上角可以看到)。
body的写法是:<body>页面内容</body> ,网页的主体布局就在body里面进行。
7、脚<footer>······</footer>
最后放入一些标准化底部样式的地方,比如友情链接,比如网站备案等等等等。

最后,别忘了把这些部分组成一体----网页,所以咱们就用<html></html>把他们给包起来。
好了,咱们来大体看看网页的结构组合起来是啥样的:
示例代码:
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>标题<title> <meta name="keywords" content="关键字" /> <meta name="description" content="本页描述或关键字描述" /> </head> <body> ..........内容.......... </body> <footer> </footer> </html>
解析:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
content(内容类型):这个网页的格式是文本的,网页模式
charset(编码):这个网页的编码是gb2312,中文编码,需要注意的是这个是网页内容的编码,而不是文件本身的,其他类型的编码中文可能会出现乱码。编码通常会出现gb2312以及utf—8两种规范,utf—8比较贴近于国际标准,而如果这个站只针对中国的话,可以选择gb2312。
<meta name="keywords" content="关键字" />
keywords是网页关键词,以前搜索引擎非常重视抓取这个东西,可是因为很多站长过度优化关键词,现在已经不那么重要了。
<meta name="description" content="本页描述或关键字描述" />
description是网页描述,介绍这个网页的大概内容。


更多建议: