
 免费 AI IDE
免费 AI IDE
Albury在本篇文章中,你将会了解 ibmdpy4nps 包是什么,以及它是如何帮助机器学习工程师和数据科学家在 Netezza 中执行他们的自定义 ML 和分析功能。Netezza On-Prem 和 Netezza 云版本都支持此功能,提供跨平台的无缝 One Netezza 体验。
介绍
为什么需要数据库内分析?
对数据库内分析的需求是众所周知的。利用 MPP 硬件进行更快处理的强大功能以及不将数据移出数据库的便利性使得 ML 工程师和数据科学家在像 Netezza® 这样的 MPP 数据库中运行分析非常有吸引力。
ibmdbpy4nps 与 Netezza 数据库内分析有何不同
Netezza 数据库内分析 (INZA) 是一个极其强大且全面的分析包,它提供了多个足以处理大多数 ML 步骤的 SQL 例程。但是,用户仅限于包中可用的内容。例如,用户可能希望使用他最喜欢的 Python ML 库中可用的最新算法,而不是可用的 INZA 算法来解决 ML 问题。或者他可能想对数据集应用一些自定义转换,这在 INZA 中不可用。这就是 ibmdbpy4nps 包的用武之地。它构建在 Netezza 分析可执行技术之上,允许用户通过简单的 Python 接口直接在数据库内执行自定义 ML 代码。使用 ibmdpy4nps,具有灵活性(用户在数据库内执行的内容方面不受限制),以及速度(你仍然不在客户端运行它,而是在数据库内部运行它)。用户还可以使用 Pandas 数据框样式的抽象连接到数据库表,并将其用于数据探索(已包含多个标准 Pandas 数据框操作的 SQL 转换)。
架构概述如下所示。
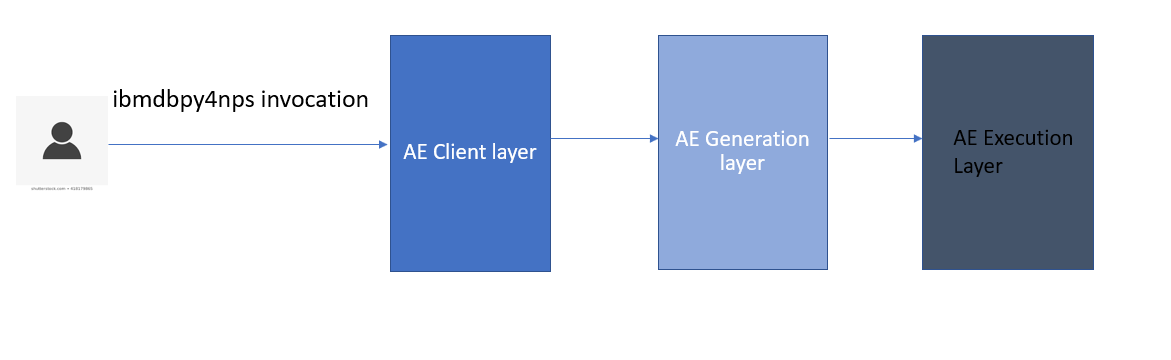
三个架构层一起(如下所述)为用户提供无缝体验,将客户端代码作为数据库内的分析可执行文件推送。用户只需通过 ibmdbpy4nps 包中提供的 Python 模块调用与分析可执行客户端层交互。
- 客户端层——提供用户可以使用所需参数导入和调用的 Python 模块。
- 生成层 — 将客户端的 Python 调用转换为基于分析可执行文件的代码,并添加调用预先存在的用户定义函数所需的 SQL。
- 执行层 — 提供预先存在的用户定义函数,执行 SQL,并运行处理执行的分析可执行启动程序。
这个包为数据库内分析提供了什么
- 允许用户使用 Pandas 风格的数据框抽象连接到数据库表。
- 支持使用内置 SQL 转换(再次使用 Pandas 数据框样式)的数据库内数据探索。
- 支持直接在数据库中执行自定义 ML 代码(通过简单的 Python 接口)
用例
场景
虽然在数据库中推送任何自定义代码在技术上是可行的,但它可能并非一直都是最佳的。Netezza 以其大规模并行处理能力而闻名。创建表时,数据通常分布在不同的数据切片上,并且在这些数据切片(在工作节点上)中的每一个上并行执行 SQL 操作,然后再将它们聚合到主机上。当用例旨在利用 Netezza 的并行性时,这是理想的选择。一些示例场景:
- 假设你需要对数据库表的每条记录应用自定义数据转换。这不需要在应用例程之前在一个地方聚合数据,因此它可以在不同的数据切片上并行执行。这是一个最佳方案。
- 假设你需要针对整个数据集构建 ML 模型。这要求在应用模型构建代码之前将数据聚合在一处。这限制了 Netezza 并行运行事物的范围。这不是最佳方案。
- 假设你的数据可以分区,你的目标是为每个分区构建 ML 模型,每个分区都是一个独立的数据集。在应用模型构建例程之前,这不需要将数据聚合在一处。你可以通过为每个分区并行构建模型来利用 Netezza 并行性。这是一个最佳方案。
- 假设你需要探索数据,例如收集数据集的统计信息。这要求在应用例程之前将数据聚合在一处,并限制 Netezza 并行运行事物的范围。这不是最佳方案。然而,鉴于这是一项常见任务,我们已经为大多数使用 Pandas 数据帧抽象的数据探索操作提供了数据库内 SQL 实现,用户可以从中受益。
安装
- 在客户端(在 Python 环境中):使用
pip install ibmdbpy4nps. - 在服务器端(Netezza 服务器):安装从 11.2.1.0 开始的任何 INZA 版本:INZA 自定义(AE 启动器、模板、预注册的 SQL 函数等)在 11.2.1.0 开始的 INZA 版本中可用以支持 ibmdbpy4nps 包调用。
- 在客户端设置 ODBC 或 JDBC 连接
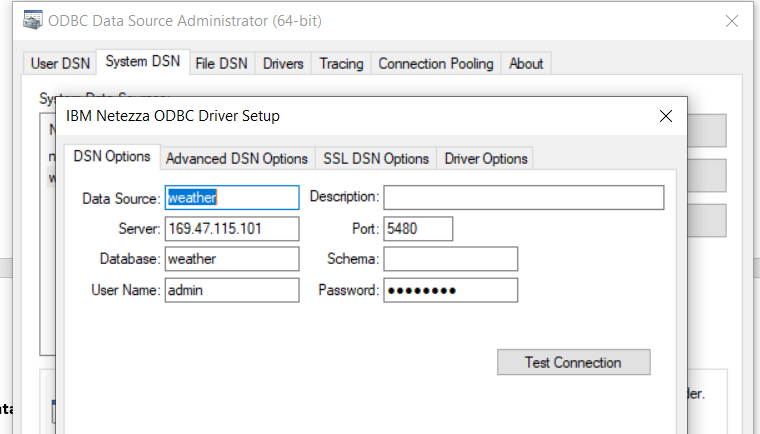
ODBC 连接:按照安装和配置 ODBC 部分中的步骤设置和配置 ODBC 数据源连接。
例如,下图(在 Windows 中)显示了为“weather”数据库设置的数据源“weather”。
JDBC 连接:IBM 知识中心在安装和配置 JDBC部分中描述了如何在你的客户端上安装 Netezza JDBC 驱动程序。下载并安装文件 nzjdbc3.jar 后,你必须将其位置包含在 CLASSPATH 环境变量的值中:
export CLASSPATH=<path-to-nzjdbc3.jar>:$CLASSPATH
连接到数据库
用户可以访问具有数据框抽象的数据库表,如下所示:
导入包
from ibmdbpy4nps, `import IdaDataBase, IdaDataFrame
连接数据库(weather是数据源名称)
idadb = IdaDataBase('weather', 'admin', 'password')
连接到数据库内的表(WEATHER 是数据库表名)
idadf = IdaDataFrame(idadb, 'WEATHER')
注意:以下是将天气 CSV加载到 Netezza 服务器上的天气表中的步骤。
- 创建一个表:
- 将 CSV 加载到表中:
- 对于没有标识列的表(如上面的天气表),创建一个标识列并将值设置为rowid:
create table weather (date Date, Location VARCHAR(100), MinTemp REAL, MaxTemp REAL, Rainfall REAL, Evaporation REAL,Sunshine REAL, WindGustDir VARCHAR(20), WindGustSpeed INTEGER, WindDir9am VARCHAR(10), WindDir3pm VARCHAR(10), WindSpeed9am INTEGER, WindSpeed3pm INTEGER, Humidity9am INTEGER, Humidity3pm INTEGER, Pressure9am REAL, Pressure3pm REAL, cloud9am VARCHAR(10), cloud3pm VARCHAR(10), Temp9am REAL, Temp3pm REAL, RainToday VARCHAR(10), RISK_MM REAL, RainTomorrow VARCHAR(10));nzload -df weatherAUS.csv -t weather -db weather -pw password -nullValue NA -boolStyle Yes_No -skipRows 1 -delim , -dateStyle MDY -dateDelim '/' alter table weather add column id bigint; update weather set id=rowid; 使用内置 SQL 翻译探索数据
本节对应于第四个用例,其中用户有兴趣探索或收集有关数据的一些统计信息。ibmdbpy4nps 包构建在 ibmdbpy 包之上,并支持多个内置的 Pandas 风格的数据帧操作。下面显示了一些示例。
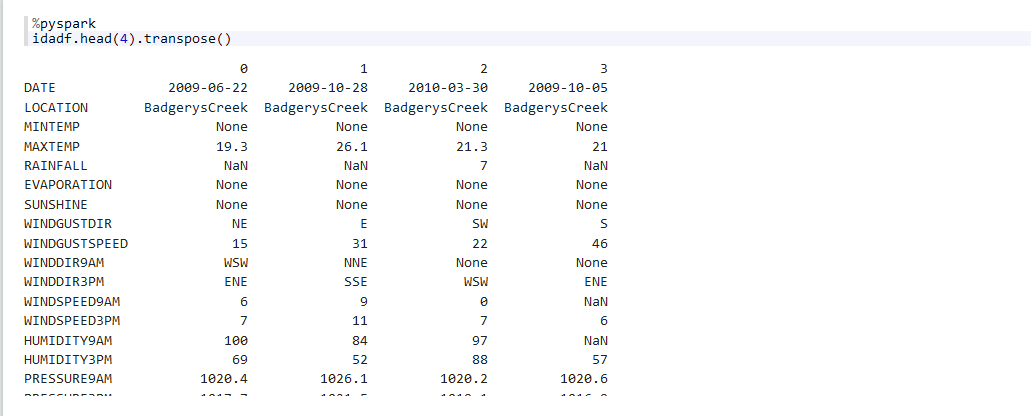
idadf.head()— 返回前n行
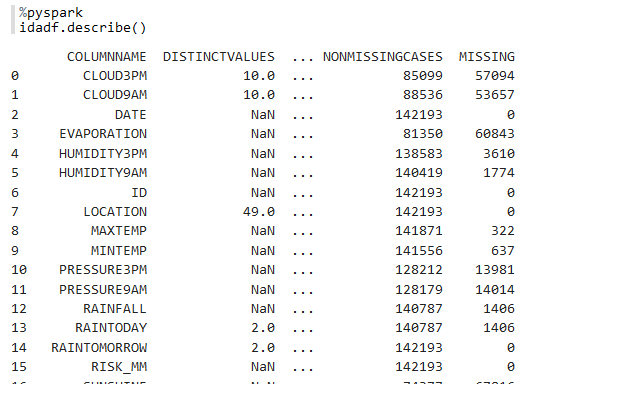
idadf.describe() — 返回列的各种统计信息
idadf.corr() — 返回列的成对相关性

上面的代码片段使用相关值生成可视化热图(就像本地 pandas 一样df.corr())。
在数据库内执行自定义分析/机器学习功能
在本节中,你将看到如何在数据库中执行自定义 ML 代码(用例 1-3)。
NZInstall – 在 Netezza 上安装软件包
实用程序开发人员需要的一项重要功能是能够在其 ML 函数中使用 Python 包之前安装它们。NZInstall 对此有所帮助。它接受一个包名并返回一个输出代码来指示是否安装了包。输出 0 表示软件包已成功安装在 Netezza 上。
from ibmdbpy4nps.ae.install import NZInstall
# specify the package_name depending on your requirement
package_name=’pandas’
idadb = IdaDataBase('weather', 'admin', 'password')
nzinstall = NZInstall(idadb, package_name)
result = nzinstall.getResultCode()NZFunApply
对表数据的每一行应用函数。这对应于第一个用例,其中用户有兴趣在数据库表的每条记录上应用自定义数据转换。
示例场景:将天气表中的 MAXTEMP 列从摄氏度转换为华氏度
默认情况下self,你要执行的用户函数可以采用两个参数:,表示分析可执行上下文,以及x,表示表的行。你可以使用x对选定的列进行操作。在下面的示例中,x[2]检索并进一步处理第三列 ( ) 以生成新值。对于你希望生成为输出的列,将它们构建为列表并用于self.output填充结果。或者,如果你只有一个结果,你可以直接将其发送到self.output。
from ibmdbpy4nps import IdaDataBase, IdaDataFrame
from ibmdbpy4nps.ae import NZFunApply
idadb = IdaDataBase('weather', 'admin', 'password', verbose=True)
idadf = IdaDataFrame(idadb, 'WEATHER')
def apply_fun(self, x):
from math import sqrt
max_temp = x[3]
id = x[24]
fahren_max_temp = (max_temp*1.8)+32
row = [id, max_temp, fahren_max_temp]
self.output(row)
output_signature = {'ID': 'int', 'MAX_TEMP': 'float', 'FAHREN_MAX_TEMP': 'float'}
nz_apply = NZFunApply(df=idadf, fun_ref = code_str_apply, output_table="temp_conversion",output_signature=output_signature, merge_output_with_df=True)
result_idadf = nz_apply.get_result()
result = result_idadf.as_dataframe()
idadb.drop_table(result_idadf.tablename)
print(result)在无法将函数作为引用发送的笔记本环境中,请将函数用引号括起来并将其分配给字符串变量。如果你的函数代码以字符串形式发送,则你还必须在NZApply调用中提及函数名称。下面提供了一个示例。
注意:要为后端 SQL 函数生成缩进的分析可执行代码,你需要在引号后立即使用函数名称,但不要在下一行。
from ibmdbpy4nps import IdaDataBase, IdaDataFrame
from ibmdbpy4nps.ae import NZFunApply
idadb = IdaDataBase('weather', 'admin', 'password', verbose=True)
idadf = IdaDataFrame(idadb, 'WEATHER')
code_str_apply = """def apply_fun(self, x):
from math import sqrt
max_temp = x[3]
id = x[24]
fahren_max_temp = (max_temp*1.8)+32
row = [id, max_temp, fahren_max_temp]
self.output(row)
"""
output_signature = {'ID': 'int', 'MAX_TEMP': 'float', 'FAHREN_MAX_TEMP': 'float'}
nz_apply = NZFunApply(df=idadf, code_str=code_str_apply, fun_name='apply_fun', output_table="temp_conversion",output_signature=output_signature, merge_output_with_df=True)
result_idadf = nz_apply.get_result()
result = result_idadf.as_dataframe()
idadb.drop_table(result_idadf.tablename)
print(result)预期结果(142193 行 x 27 列):
| 最高温度 | FAHREN_MAX_TEMP | 日期 | 风险_MM | 明天下雨 | ID | |
|---|---|---|---|---|---|---|
| 0 | 27.700001 | 81.860001 | 2008-12-16 | 0.0 | 不 | 448014 |
| 1 | 33.000000 | 91.400002 | 2008-12-22 | 0.0 | 不 | 448020 |
| 2 | 32.700001 | 90.860001 | 2008-12-28 | 0.0 | 不 | 448026 |
| 3 | 28.799999 | 83.839996 | 2009-01-03 | 0.0 | 不 | 448032 |
| 4 | 28.400000 | 83.120003 | 2009-01-09 | 0.0 | 不 | 448038 |
| … | … | … | … | … | … | … |
| 142188 | 32.900002 | 91.220001 | 2015-12-02 | 0.0 | 不 | 589631 |
| 142189 | 37.099998 | 98.779999 | 2015-12-08 | 0.2 | 不 | 589637 |
| 142190 | 39.500000 | 103.099998 | 2015-12-14 | 3.8 | 是的 | 589643 |
| 142191 | 30.299999 | 86.540001 | 2015-12-20 | 4.8 | 是的 | 589649 |
| 142192 | 36.299999 | 97.339996 | 2016-02-06 | 0.0 | 不 | 589692 |
NZFunT申请
这对应于用户有兴趣执行复杂功能的第二个用例——例如,针对整个可用行构建 ML 模型。这将导致我们在以下部分中描述的两种变体,针对切片数据构建模型或针对整个表数据构建模型。
a) 对数据的每个切片应用该函数
数据切片是表数据的一部分。Netezza 根据创建表时指定的列将数据分配到不同的切片。如果未指定列,则第一列将被视为分布列。因此,在使用NZFunTApply. 否则,你可能会在将函数应用于你不想要的切片时产生意外结果。
示例场景:转换数据,构建 ML 模型,并测量模型的准确性
让我们使用天气数据集编写一个函数来解决上述情况。天气数据集包含来自澳大利亚多个地点的 10 年每日天气观测数据。数据集中有 48 个唯一位置,并且RainTomorrow是要预测的目标变量(第二天下雨了吗?)。次日降雨预测是通过对目标变量 训练分类模型来完成的RainTomorrow。我们的目标是编写一个函数来执行三个步骤:转换数据(通过为空值分配默认值来估算列),构建 ML 模型(为转换后的数据构建决策树分类器),然后测量准确性(计算三倍的 CV 准确度分数)。
请注意,该函数默认获取两个参数:(self表示分析可执行上下文)和df(传入切片数据的数据帧)。使用self.output打印数据集的结果大小、第一条记录的位置和准确度。
from ibmdbpy4nps import IdaDataBase, IdaDataFrame
from ibmdbpy4nps.ae import NZFunTApply
idadb = IdaDataBase('weather', 'admin', 'password', verbose=True)
idadf = IdaDataFrame(idadb, 'WEATHER')
code_str_host_spus="""def decision_tree_ml(self, df):
from sklearn.model_selection import cross_val_score
from sklearn.impute import SimpleImputer
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
import numpy as np
location = df.LOCATION[0]
# data preparation
imputed_df = df.copy()
ds_size = len(imputed_df)
imputed_df['CLOUD9AM'] = imputed_df.CLOUD9AM.astype('str')
imputed_df['CLOUD3PM'] = imputed_df.CLOUD3PM.astype('str')
imputed_df['SUNSHINE'] = imputed_df.SUNSHINE.astype('float')
imputed_df['EVAPORATION'] = imputed_df.EVAPORATION.astype('float')
#remove columns which have only null values
columns = imputed_df.columns
for column in columns:
if imputed_df[column].isnull().sum()==len(imputed_df):
imputed_df=imputed_df.drop(column, 1)
columns = imputed_df.columns
for column in columns:
if (imputed_df[column].dtype == 'float64' or imputed_df[column].dtype == 'int64'):
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
imputed_df[column] = imp.fit_transform(imputed_df[column].values.reshape(-1, 1))
if (imputed_df[column].dtype == 'object'):
# impute missing values for categorical variables
imp = SimpleImputer(missing_values=None, strategy='constant', fill_value='missing')
imputed_df[column] = imp.fit_transform(imputed_df[column].values.reshape(-1, 1))
imputed_df[column] = imputed_df[column].astype('str')
le = LabelEncoder()
#print(imputed_df[column].unique())
le.fit(imputed_df[column].unique())
# print(le.classes_)
imputed_df[column] = le.transform(imputed_df[column])
X = imputed_df.drop(['RISK_MM', 'RAINTOMORROW'], axis=1)
y = imputed_df['RAINTOMORROW']
# Create a decision tree
dt = DecisionTreeClassifier(max_depth=5)
cvscores_3 = cross_val_score(dt, X, y, cv=3)
self.output(ds_size, location, np.mean(cvscores_3))
"""由于我们要在每个数据切片上应用该函数,所以我们将parallel=True在模块调用中进行选择。
output_signature = {'DATASET_SIZE': 'int', 'LOCATION':'str', 'CLASSIFIER_ACCURACY':'double'}
nz_fun_tapply = NZFunTApply(df=idadf, code_str=code_str_host_spus, fun_name ="decision_tree_ml", parallel=True, output_signature=output_signature)
result = nz_fun_tapply.get_result()
result_idadf = nz_apply.get_result()
result = result_idadf.as_dataframe()
idadb.drop_table(result_idadf.tablename)
print(result)请注意,我们在结果中有多行(对应于创建表时分配的数据切片的数量)。第一列是数据集的大小,第二列是数据集中第一条记录的位置,第三列是构建的分类器的准确率。
| 数据集_大小 | 地点 | 分类器_准确度 | |
|---|---|---|---|
| 0 | 23673 | Albury | 0.824822 |
| 1 | 23734 | Albury |
0.827126 |
| 2 | 23686 | Albury |
0.813898 |
| 3 | 23706 | Albury |
0.818485 |
| 4 | 23739 | Albury |
0.832175 |
| 5 | 23655 | Albury |
0.826168 |
b) 应用于数据集的函数
您可能希望将该函数应用于整个数据集而不是切片。这意味着在应用该功能之前,需要将数据聚合到一个地方。这不是最佳方案,但parallel=False为了完整起见,我们确实提供了此选项(使用)。
output_signature = {'DATASET_SIZE': 'int', 'LOCATION':'str', 'CLASSIFIER_ACCURACY':'double'}
nz_fun_tapply = NZFunTApply(df=idadf, code_str=code_str_host_spus, fun_name ="decision_tree_ml", parallel=False, output_signature=output_signature)
result = nz_fun_tapply.get_result()
result_idadf = nz_apply.get_result()
result = result_idadf.as_dataframe()
idadb.drop_table(result_idadf.tablename)
print(result)因为我们选择parallel=False在完整数据集上执行该函数,所以你只能在结果中看到一行。第一列是数据集的大小,第二列是数据集中第一条记录的位置,第三列是构建的分类器的准确率。
| 数据集_大小 | 地点 | 分类器_准确度 |
|---|---|---|
| 142193 | Albury |
0.827115 |
注意:对于复杂的功能,最好先在客户端测试,然后再在服务器上运行。可以使用选择查询(select * from weather limit 1000)下载一个小的子集(比如 1,000 条记录),在客户端数据帧上测试该函数,然后将该函数推送到服务器以针对整个数据集执行。
NZFunGroupedApply
根据用户的选择在运行时计算的每个分区上应用该函数。
本节对应于第四个用例,其中用户有兴趣执行复杂的功能,例如为他选择的分区构建 ML 模型。
在这种情况下,你的函数将应用于运行你提供给NZFunGroupedApply的输入列(索引参数)计算的每个分区。Netezza 数据切片将在运行时重新生成,以便每个切片仅包含一组或多组指定的列。由于这不需要在应用该函数之前将数据聚合在一处,因此这是一种最佳方案。此外,现实世界的 ML 设置需要在定义组时进行控制。因此,这是利用 Netezza 并行性处理复杂 ML 功能的最推荐选项。每个组/分区都被视为独立的数据集,并且针对这些分区并行执行该函数。
虽然NZFunTApply也将函数应用于并行数据切片 ( parallel=True) 选项,但有一些区别:
-
NZFunTApply使用静态切片,这意味着这些切片可能不是你的场景所需的数据排列。 - 该函数是针对整个切片执行的,而不是针对切片中的组执行的。
示例场景:转换数据、构建 ML 模型并为模型评分
让我们再次使用天气数据集来编写解决上述情况的函数。请记住,数据集中有 48 个唯一位置(产生 48 个分区)并且RainTomorrow是要预测的目标变量。我们的目标是编写一个函数来为每个分区执行三个步骤:转换数据(通过为空值分配默认值来估算列),构建 ML 模型(为转换后的数据构建决策树分类器),然后评分模型(预测RAINTOMORROW的值)。
请注意,该函数默认获取两个参数:self,代表分析可执行上下文)和df(传入切片数据的数据帧);结果 ID、数据集大小、第一条记录的位置列值和预测值用 打印self.output。
from ibmdbpy4nps import IdaDataBase, IdaDataFrame
from ibmdbpy4nps.ae import NZFunGroupedApply
idadb = IdaDataBase('weather', 'admin', 'password', verbose=True)
idadf = IdaDataFrame(idadb, 'WEATHER')
code_str_host_spus="""def decision_tree_ml(self, df):
from sklearn.model_selection import cross_val_score
from sklearn.impute import SimpleImputer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import numpy as np
# data preparation
imputed_df = df.copy()
ds_size = len(imputed_df)
temp_dict = dict()
columns = imputed_df.columns
for column in columns:
if column=='ID':
continue
if (imputed_df[column].dtype == 'float64' or imputed_df[column].dtype == 'int64'):
if imputed_df[column].isnull().sum()==len(imputed_df):
imputed_df[column] = imputed_df[column].fillna(0)
else :
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
transformed_column = imp.fit_transform(imputed_df[column].values.reshape(-1, 1))
imputed_df[column] = transformed_column
if (imputed_df[column].dtype == 'object'):
# impute missing values for categorical variables
imp = SimpleImputer(missing_values=None, strategy='constant', fill_value='missing')
imputed_df[column] = imp.fit_transform(imputed_df[column].values.reshape(-1, 1))
imputed_df[column] = imputed_df[column].astype('str')
le = LabelEncoder()
le.fit(imputed_df[column])
# print(le.classes_)
imputed_df[column] = le.transform(imputed_df[column])
temp_dict[column] = le
# Create a decision tree
dt = DecisionTreeClassifier(max_depth=5)
X = imputed_df.drop(['RISK_MM', 'RAINTOMORROW'], axis=1)
y = imputed_df['RAINTOMORROW']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.25, random_state=42, stratify=y)
dt.fit(X_train, y_train)
accuracy = dt.score(X_test, y_test)
pred_df = X_test.copy()
y_pred= dt.predict(X_test)
pred_df['RAINTOMORROW'] = y_pred
pred_df['DATASET_SIZE'] = ds_size
pred_df['CLASSIFIER_ACCURACY']=round(accuracy,2)
original_columns = pred_df.columns
for column in original_columns:
if column in temp_dict:
pred_df[column] = temp_dict[column].inverse_transform(pred_df[column])
#print(pred_df)
def print_output(x):
row = [x['ID'], x['RAINTOMORROW'], x['DATASET_SIZE'], x['CLASSIFIER_ACCURACY']]
self.output(row)
pred_df.apply(print_output, axis=1)
"""
output_signature = {'ID':'int', 'RAINTOMORROW_PRED' :'str', 'DATASET_SIZE':'int', 'CLASSIFIER_ACCURACY':'float'}
nz_groupapply = NZFunGroupedApply(df=idadf, code_str=code_str_host_spus, index='LOCATION', fun_name="decision_tree_ml", output_signature=output_signature, merge_output_with_df=True)
result_idadf = nz_apply.get_result()
result = result_idadf.as_dataframe()
idadb.drop_table(result_idadf.tablename)
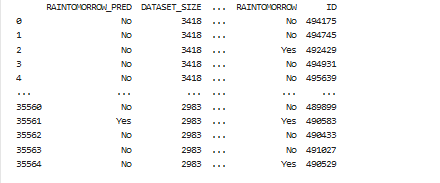
print(result)你应该会看到如下所示的结果。请注意,结果列已通过merge_output_with_df=True选项与原始 df 列合并。
Netezza安装
在 Netezza 上安装软件包。实用程序开发人员需要的一项重要功能是能够在其 ML 函数中使用 Python 包之前安装它们。NZInstall对此有帮助。它接受一个包名并返回一个输出代码来指示是否安装了包。输出 0 表示软件包已成功安装在 Netezza 上。
例子:
from ibmdbpy4nps.ae.install import NZInstall
idadb = IdaDataBase('weather', 'admin', 'password')
nzinstall = NZInstall(idadb, package_name)
result = nzinstall.getResultCode()结论
在本文中,我们展示了如何将自定义 ML 推送到 Netezza(无论是内部部署还是云版本)。如示例中所示,使用 ibmdbpy4nps,用户将能够在数据库中无缝运行他们的自定义代码,就像在他们最喜欢的 IDE 或 Notebook 环境中运行一样。这为用户提供了数据库内分析的性能、不将数据移出数据库的便利性以及编写自定义 Python 函数的灵活性。我们得出的结论是,如果出现以下情况,用户应该考虑针对他们的用例使用下推方法:
- 数据有分区,如果每个分区都被视为一个独立的数据集。
- 模型构建或分析需要在此类分区数据集上并行执行。
- 分区计数足够高(大于或等于 Netezza 配置中的工作节点数)以利用并行性。



