
 免费 AI IDE
免费 AI IDE
很多小伙伴在刚开始学习使用爬虫爬取网页的时候都能够爬取一个页面完整内容正确的html界面下来。小编刚开始的时候也是如此,直到小编某天碰上了自家网站的数据,才知道自己还是太年轻了。为什么呢?因为小编爬到的页面一半是正常的html页面和标签,另一半夹杂着奇怪的乱码。今天我们就来讲解一下爬虫爬到乱码怎么办吧!
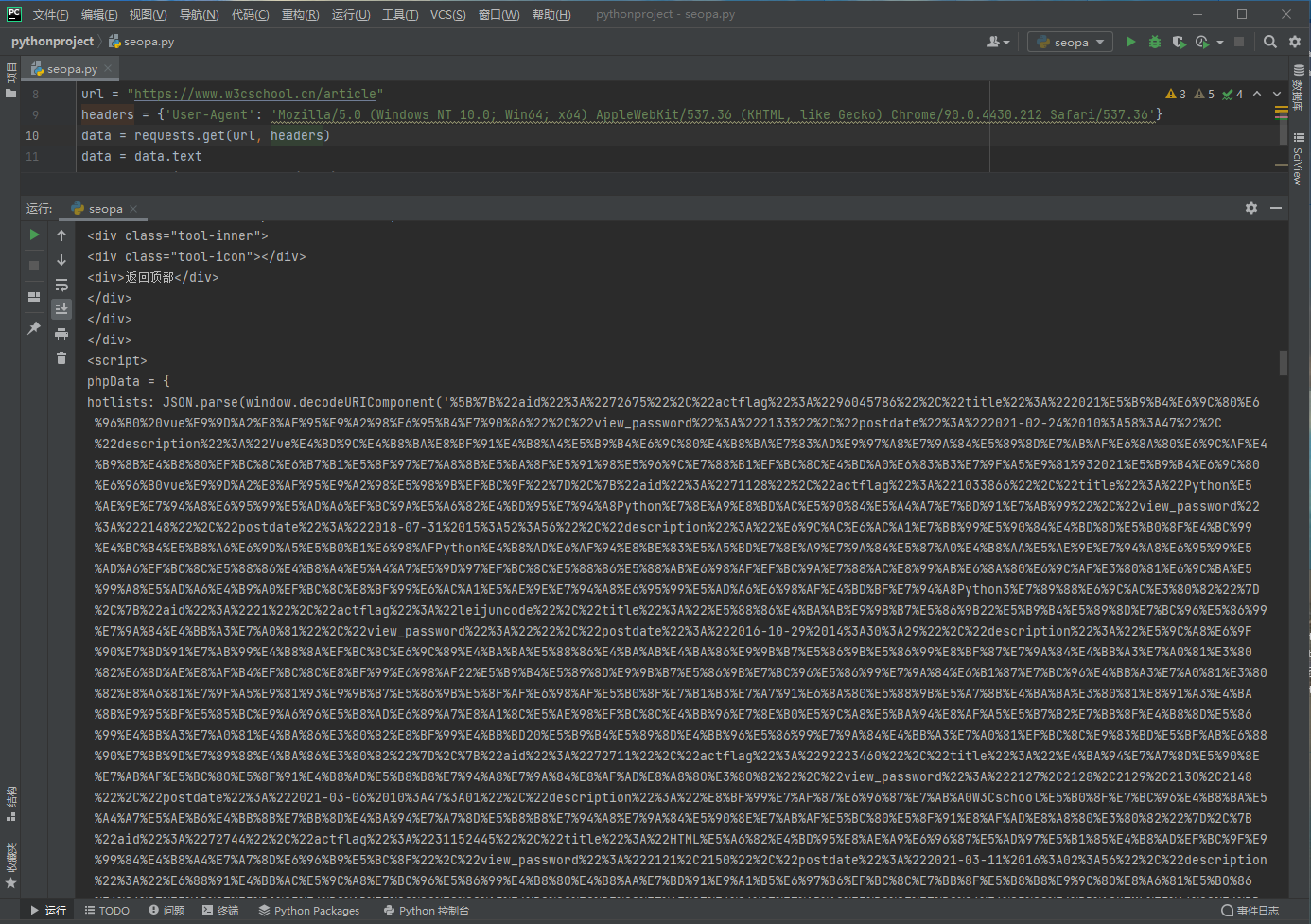
案例
思路
很多情况出现乱码的原因其实还是用户(开发者)本身造成的。使用了错误的方式打开了一个文件,就会出现乱码。比如说文本文件的UTF-8格式的文件被错误地使用GBK方式打开等。而上面的案例中实际上也是一种错误的打开方式(或者说,没有完全打开)。实际上,看到上面的代码我们第一反应是应该去查找这是什么代码。根据小编的经验(没有经验的也可以百度),这应该是URL编码,然后小编找了站长工具进行测试后也确定了该编码方式是URL编码。
什么是URL编码?
URL编码是一种特殊的编码形式,因为最开始应用于URL中所以得名URL编码。我们知道URL中是不能出现中文还有其他非英文字符的(也可以理解为不能出现非ASCII码表的字符),但我们又确实需要在URL中输入一些非ASCII码表字符(我们知道,GET方式传参是将参数添加到URL后面的,如果不能在URL中输入非ASCII字符,那么就意味着GET传参不能实现其他文字的传参),于是就出现了URL编码的标准。URL编码的方式是把非ASCII码字符用%和可用的ASCII字符表示出来,这样就能用这些ASCII字符去表示非ASCII字符了。

小伙伴们会说,你看这地址栏不是也出现了中文了吗?其实这是浏览器的优化,为了让你清楚这个链接,浏览器在地址栏会将URL编码进行解码,所以你看到的会是中文
如何解URL编码
在前端开发中对于这种数据一般是用JavaScript编写一个解编码的程序去进行解编码(现在有很多现成的解编码的js代码段),小型的数据我们可以去站长工具里面解编码(这种方式通常用来验证是否是URL编码)。但是我们是在爬虫爬取数据的时候需要对这些URL代码进行解编码,所以我们要用python的方式去解决。
在python中有一个自带的urllib库,我们知道这个库的request模块可以进行请求,parse模块可以对html代码进行解析。实际上它也可对URL编码进行解编码,以下是解编码的代码示例,各位小伙伴可以拿去做参考。
import requests
import urllib.parse
url = "https://www.w3cschool.cn/article"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
data = requests.get(url, headers)
data = data.text
data =urllib.parse.unquote(data)
print(data)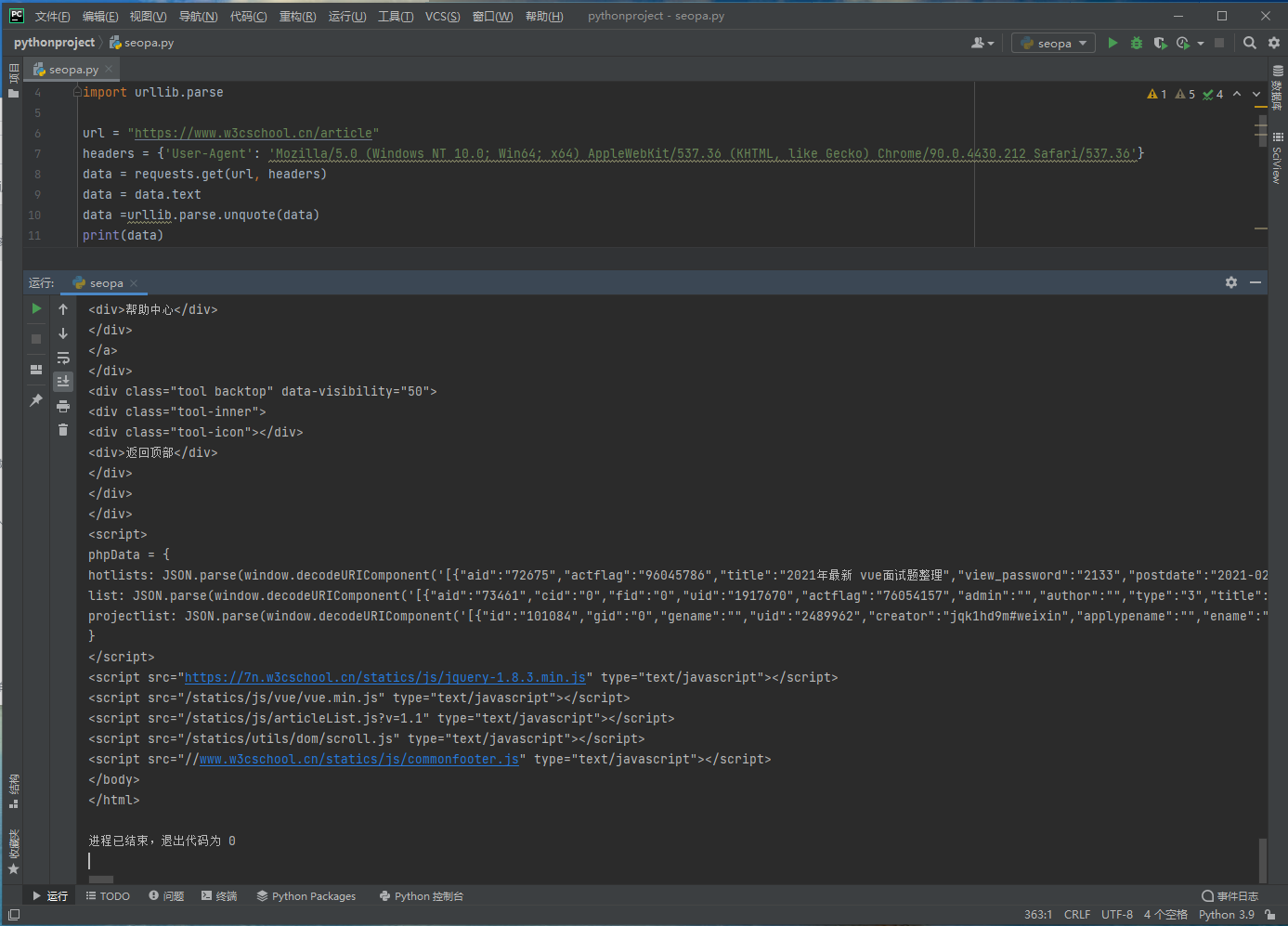
可以看到原本的乱码变成了一段可阅读的代码,说明我们解码成功了。
小结
以上就是关于URL编码和URL编码解码的全部内容,希望能给各位小伙伴带来一丝帮助。也希望各位小伙伴能关注支持W3Cschool!



