
 免费 AI IDE
免费 AI IDE
本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
导语
本文将在此基础上介绍LSTM网络。最后举一个类似“Python学写作”的例子来实现文本生成,如生成诗歌、小说等等。
让我们愉快地开始吧~~~
参考文献
Understanding LSTM Networks:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
相关文件
百度网盘下载链接: https://pan.baidu.com/s/16hjmw1NtU9Oa4iwyj4qJuQ
密码: gmpi
开发工具
Python版本:3.6.4
相关模块:
tensorflow-gpu模块;
numpy模块;
以及一些Python自带的模块。
其中TensorFlow-GPU版本为:
1.7.0
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
另外,TensorFlow-GPU的环境搭建请自行参考相关的网络教程,注意版本和驱动严格对应即可。
原理介绍
一. RNNs
人们的思维总是具有延续性的,比如当你阅读这篇文章时,你对每个词的理解都会依赖于你前面看到的一些词,而不是把你前面看的内容全部抛弃,再去理解每个词。而传统的神经网络(CNN)无法做到这一点,因此有了循环神经网络(RNNs)。
在RNNs中,存在循环操作,使得它们能够保留之前学习到的内容:
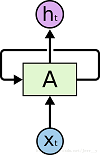
在上图网络结构中,对于矩形块A的那部分,通过输入Xt(t时刻的特征向量),它会输出一个结果ht(t时刻的状态或者输出),网络中的循环结构使得当前状态作为下一时刻输入的一部分。
将RNNs在时间步上进行展开,就可以得到下图:
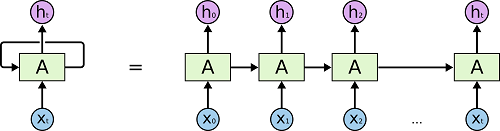
也就是“Python实现简单的机器翻译模型”一文中所使用的RNNs链状的结构。显然,这样的结构是有利于处理序列相关问题的。近年来,其在语音识别、语言翻译等等领域都取得了巨大的成功。
而RNNs的成功,主要归功于LSTMs这种特殊RNNs结构的使用,而非普通的RNNs结构。
二. LSTMs
全称为Long Short Term Memory networks.
即长短期记忆网络。
普通RNNs的局限性在于当我们所要预测的内容和相关信息之间的间隔很大时,普通RNNs很难去把它们关联起来:
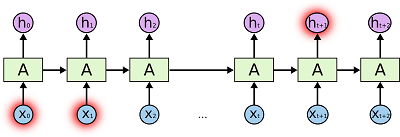
尽管从理论上来讲,只要参数合适,还是可以解决长时期依赖关系无法很好联系这一问题的,但具体实现起来似乎并不容易,至少目前为止是不容易的。
幸运的是,LSTMs能够很好地解决这一问题。它被设计的初衷就是为了能够记住长时期内的信息。
循环神经网络是由相同结构的神经网络模块进行复制而形成的。在标准的RNNs中,神经网络模块的结构非常简单,比如可以由单一的tanh层构成:
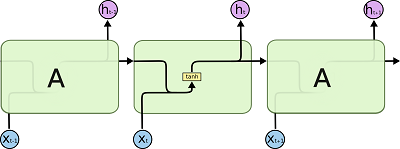
LSTMs也有类似的结构,不过神经网络模块的结构变得相对复杂了一些:
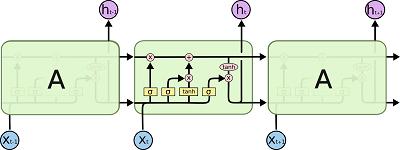
接下来,我们来详细介绍一下这个结构。首先,我们来定义一下用到的符号:

粉红色的圈:
代表向量加之类的逐点操作;
黄色矩形框:
代表神经网络层;
普通的线:
用于携带并传递向量;
合并的线:
代表对两条线上所携带的向量进行合并;
分开的线:
代表将线上所携带的向量复制后传给两个地方。
2.1 LSTMs的核心思想
假设一个绿色的框就是一个cell。
向量通过结构图最上面的那条贯穿cell的水平线穿过整个cell,而cell仅对其做了少量的线性操作:
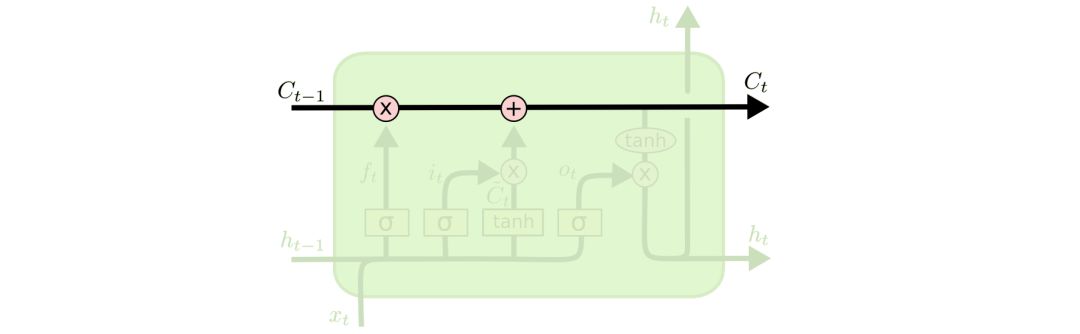
显然,这样的结构能够很轻松地让信息从整个cell中穿过而不发生变化。
当然,只有一条水平线是无法实现添加或者删除信息的,也就是实现让信息有选择地通过cell,这需要通过一种叫做门(gates)的结构来实现。
门结构主要由一个sigmoid神经网络层和一个逐点相乘的操作来实现:
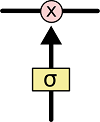
sigmoid层输出的向量每个元素都是介于0和1之间的实数,表示此时通过的信息的权重,当其为0时表示“此时不让任何信息通过”,为1时表示“此时让所有信息通过”。每个LSTM都有三个这样的门结构,来实现保护和控制信息。
2.2 逐步理解LSTM
遗忘门(forget gate layer):
首先,LSTM需要决定哪些信息需要丢弃,哪些信息需要保留。这是通过一个叫做遗忘门的sigmoid层来实现的。它的输入是ht-1和xt,输出是一个数值都在0到1之间的向量,表示Ct-1中各部分信息的权重,0表示不让该部分信息通过,1表示让该部分信息全部通过。
具体而言,比如在语言模型中,我们要根据所有的上下文信息来预测下一个词。在这种情况下,每个cell的状态中都应该包含了当前主语的性别信息。这样,接下来我们才能够正确地使用代词。但是,当我们开始描述一个新的主语时,就应该把之前的主语性别给丢弃了才对。
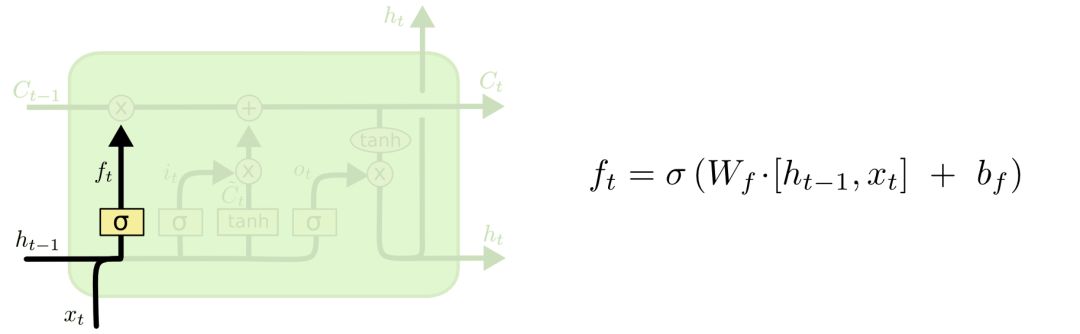
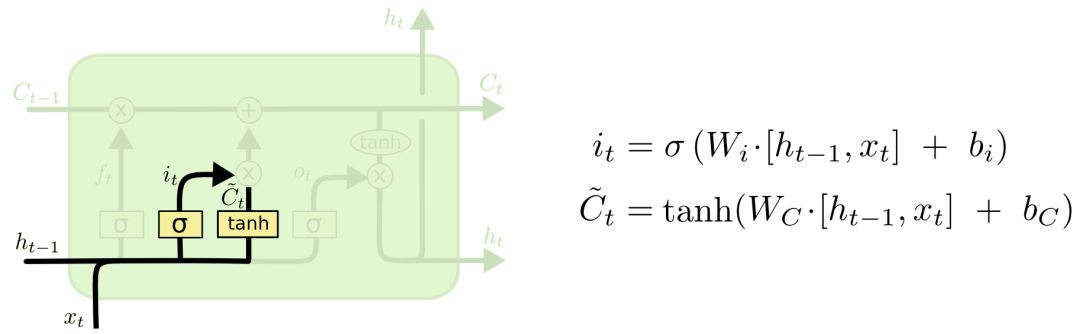
传入门(input gate layer):
其次,LSTM将决定让哪些新的信息加入到cell的状态中来。该实现分两个步骤进行:
① 用一个tanh层生成一个备选向量,用于表示获得的所有可添加信息;
② 用一个叫做传入门的sigmoid层来决定步骤①中获得的可添加信息各自的权重。
具体而言,比如在语言模型中,我们需要把新主语的性别信息添加到cell状态中,来替换掉之前的主语性别信息。
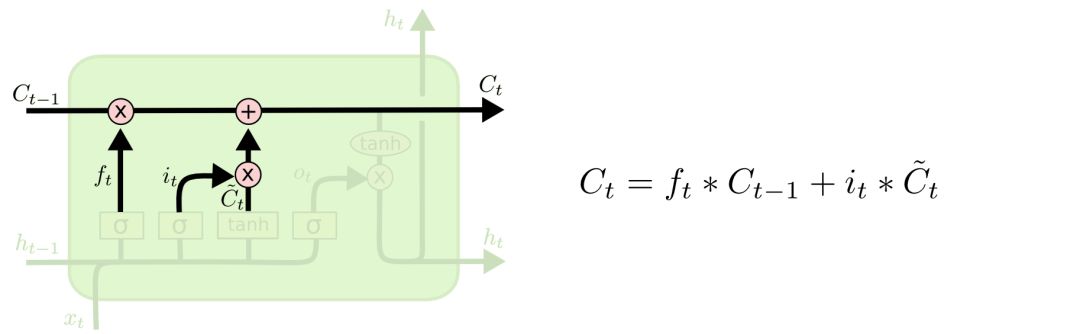
有了遗忘门和传入门,我们就能够更新cell的状态了,即把Ct-1更新为Ct。
还是以语言模型为例,假设我们的模型刚输出了一个代词,接下来可能要输出一个动词,那么这个动词应该采用单数形式还是复数形式呢?显然,我们需要把代词相关的信息和当前的预测信息都加入到cell的状态中来,才能够进行正确的预测。
具体计算方式如下图所示:
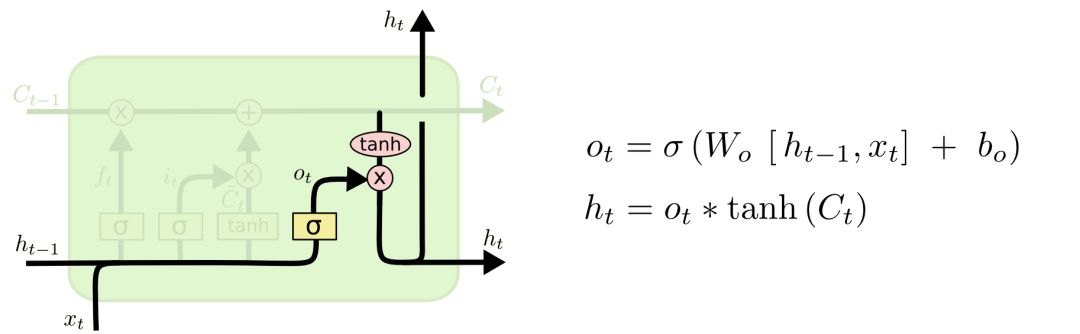
输出门(Output):
最后,我们需要决定输出值。输出值的计算方式为:
① 使用sigmoid层来决定/计算出Ct中的哪部分信息会被输出;
② 利用tanh层将Ct的取值压缩到-1到1之间;
③ 将tanh层的输出和sigmoid层的输出相乘即为最终的输出结果。
三. LSTMs的变种
① 将cell的状态作为门结构输入的一部分。
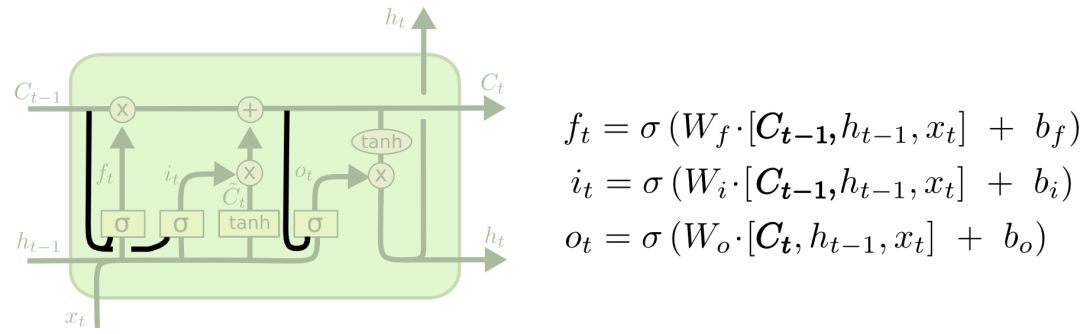
② 将遗忘门与传入门耦合,即不再分开决定要遗忘和添加的信息。
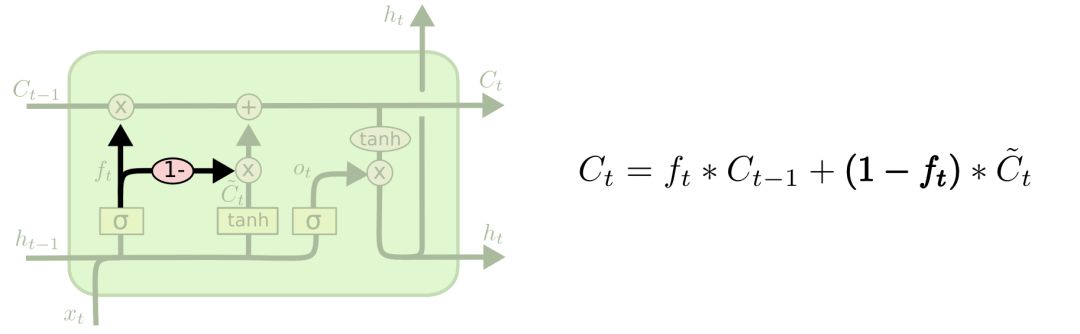
③ GRU
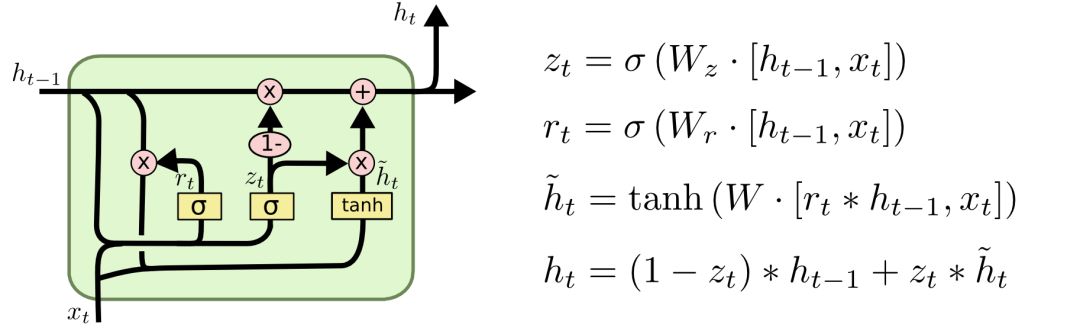
GRU模型“简化”了LSTM模型的设计,其中rt由LSTM中的遗忘门和传入门合并而得,称为重置门;zt为更新门,作用相当于LSTM中的输出门。
实际应用
为了贯彻理论与实践相结合的理念,本文将举一个简单的小例子,该例子使用的模型与“Python学写作”类似,本文不再作多余的介绍。
具体实现过程详见相关文件中的源代码。
使用演示
模型训练:
在cmd窗口运行'train.py'文件即可:
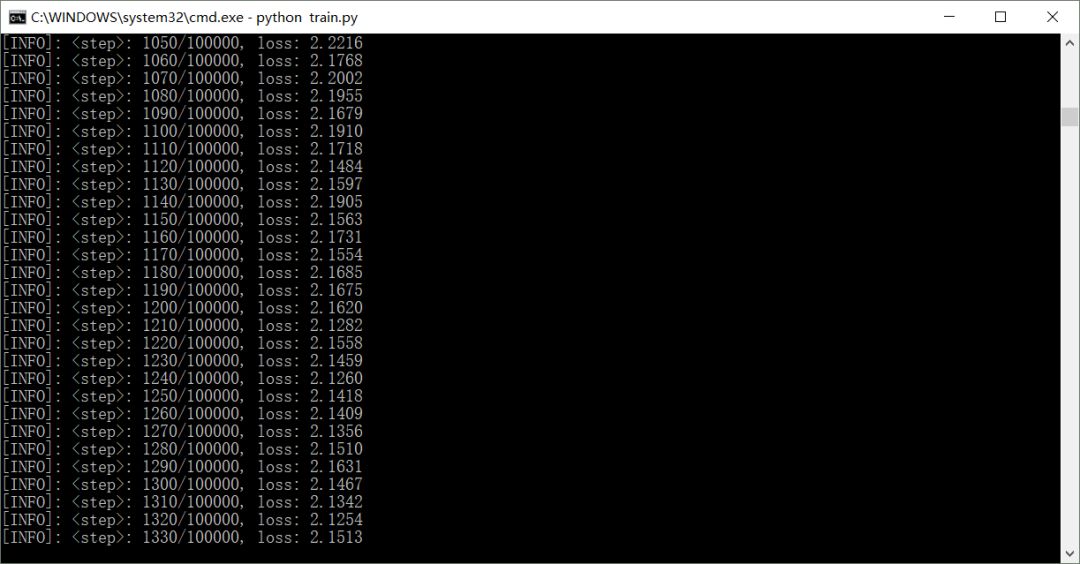
如有需要,可自行修改相关参数:
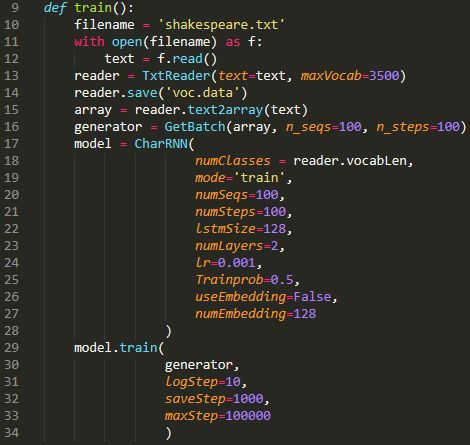
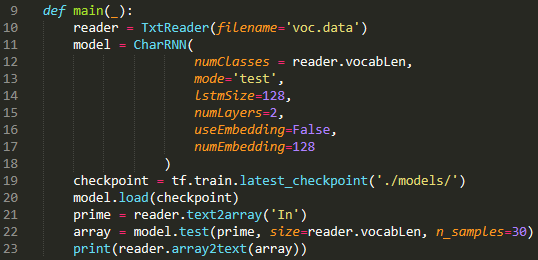
模型使用:
在cmd窗口运行“generate.py”文件即可。
注意模型参数需和train.py文件中的模型参数一致:
结果展示
生成英文文本:
以莎士比亚的作品为训练素材获得的结果:

生成中文文本:
以周杰伦的作品为训练素材获得的结果:

更多
代码截止2018-06-24测试无误。
模型比较简单,有兴趣的朋友可以在此基础上进行优化,当然RNN的作用可不仅仅是文本生成哦~
以后有机会再举其他例子吧~~~



