

很多读者看到爬虫是不是第一反应就想到了某些蛛形纲的节肢动物?其实在互联网上爬虫还有另一种解释——网页机器人。今天我们就来介绍一下这些网页机器人的分类——互联网爬虫分类和一些python爬虫基础知识吧。
一、通用爬虫
通用网络爬虫是搜索引擎抓取系统(Baidu、Google、Sogou等)的一个重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。为搜索引擎提供搜索支持。
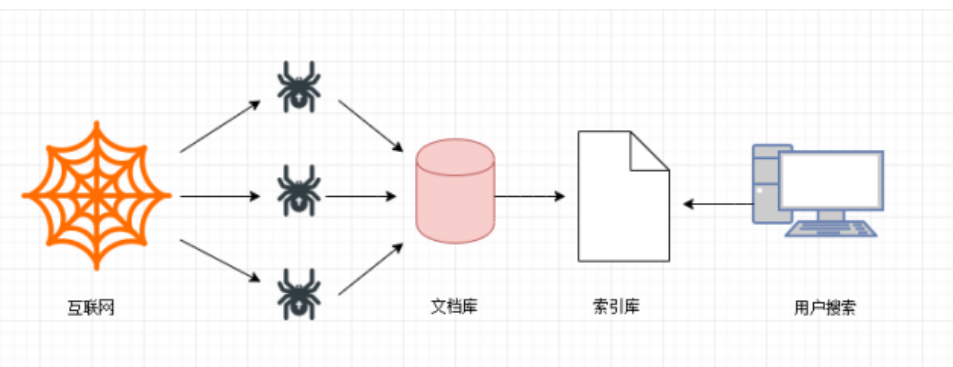
第一步
搜索引擎去成千上万个网站抓取数据。
第二步
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库(也就是文档库)。其中的页面数据与用户浏览器得到的HTML是完全—样的。
第三步
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理:中文分词,消除噪音,索引处理······
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。展示的时候会进行排名。
二、搜索引擎的局限性
- 搜索引擎抓取的是整个网页,不是具体详细的信息。
- 搜索引擎无法提供针对具体某个客户需求的搜索结果。
聚焦爬虫
针对通用爬虫的这些情况,聚焦爬虫技术得以广泛使用。聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页数据。
三、Robots协议
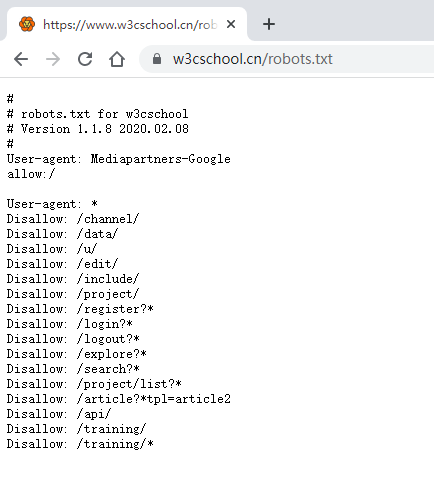
robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。——百度百科
Robots协议也叫爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots ExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
四、请求与响应
网络通信由两部分组成:客户端请求消息与服务器响应消息

浏览器发送HTTP请求的过程:

1.当我们在浏览器输入URL https://www.baidu.com的时候,浏览器发送一个Request请求去获取 https://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
2.浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
3.当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
实际上我们通过学习爬虫技术爬取数据,也是向服务器请求数据,获取服务器响应数据的过程。
小结
到此这篇python爬虫基础知识的文章就介绍到这了。
学习python爬虫可以了解一下我们最近上线的爬虫新课:Python爬虫从入门到实战_

来自百度的资深大数据工程师,各位小伙伴懂得都懂,趁现在新课打折,快快上车吧!



